


原文标题:The Math Behind Combining 50 Weak Signals Into One Winning Trade
原文作者:Roan,加密分析师
翻译、注释:MrRyanChi,insiders.bot
写在前面
去年,在入学特朗普马斯克母校 @Wharton 交换的第一个礼拜,我就和 @DakshBigShit 创立了 @insidersdotbot。得益于沃顿商学院这一优秀的土壤,以及邻近纽约的地理优势,我在四个月内和不少管理着上亿美元规模的对冲基金合伙人深入交流过。
随后,当我返回中国香港 all-in 创业,insiders.bot 已经崭露头角,这让我也有了与亚洲的量化机构深度交流的机会。
这个过程当中,我反复听到的一个词,就是「信号」。
入场信号,出场信号,等等等等。这个过程中:散户和机构之间最大的差距,不是信息量,不是资金量,而是思维框架。散户总想找到那个「一招鲜」的完美信号,机构却在用一套数学引擎把几十个「不怎么样」的信号拧成一根绳。
Binance,OKX,Bitget 等等交易平台旗下的钱包,也早早的加入了各类信号播报内容。
甚至,在 insiders.bot 创立的最早期,我们也是作为 「信号机器人」 横空出世的。而我们当时最受欢迎的 v1.2 信号,就是聚合了多个聪明钱信号的信号,收到了不少链上大佬的赞赏。预测市场交易者最喜欢的播报系统 @poly_beats,本质上也是信号。
RohOnChain 这篇文章,是我见过把「信号」这套框架讲得最清楚的一篇。我花了大量时间改写、补充、加注释,就是为了让你哪怕没有任何量化背景,也能从头到尾看懂。
第一部分:那个不存在的「完美信号」
我和一位在系统化交易领域干了二十年的基金合伙人聊天时,听到过一句让我琢磨了好几个月的话。
那天他坐在我对面,看着我们正在讨论的策略,平静地说:
「你总是在试图寻找那个永远正确的唯一信号。但那个东西根本不存在。真正能赢的交易台,是那些能把许多个『稍微有点准』的信号正确组合在一起的团队。」
他描述的这个东西,在量化界有一个 Jargon,一个非常抽象的专有名词:
Alpha 组合(Alpha Combination)。
这套框架是一道分水岭。它把那些能持续稳定赚钱的机构,和那些「明明看对了方向却依然亏钱」的散户,死死地隔开。
读完这篇文章,你会明白五件事:
1. 为什么组合 50 个弱信号,绝对碾压 1 个强信号?
2. 什么是「主动管理基本定律」?
3. 机构到底是用哪 11 个步骤,把一堆烂信号变成高胜率策略的?
4. 为什么你明明看对了方向,最后还是亏了钱?
5. 如何把这套系统完美应用在 Polymarket 上?
如果你真的想建立自己的交易优势,请不要跳过任何一个章节。这套框架只有当你把五个部分连在一起看时,才会发挥出真正的威力。
顺便说一句,这篇文章在结构上也针对 AI Agent 做了优化。欢迎把它喂给你的 Claude、Manus 或者任何一个 AI,然后立刻开始搭建你自己的量化模型。
1.1 到底什么是「信号」?
在深入数学之前,我们必须先统一语言:到底什么是「信号」?
在日常生活中,我们经常说「我感觉这个币要涨」,或者「我看好特朗普当选」。这叫观点。观点是模糊的、主观的、无法被精确回测的。
但在机构的量化框架里,信号是一个可测量的、与未来价格或概率变动具有统计学上可重复关系的数据点。
它必须满足三个条件:
可量化: 它必须是一个具体的数字。比如「过去 24 小时交易量放大了 3 倍」,而不是「最近讨论的人变多了」。
有方向: 它必须能告诉你接下来是涨还是跌,或者概率是变大还是变小。
可重复: 它不能是孤立事件,必须在历史上多次出现,并且每次出现后,市场都有类似的反应。
比如,Binance 上几个高胜率大户连续买入,买了多少,就是信号。
比如,我们 @insidersdotbot 的 v1.2 的 Skew(聪明钱看多看空比例),也是信号。
举个 Polymarket 上的例子:如果一个历史胜率超过 70% 的聪明钱钱包,突然在某个冷门合约上下注了 5 万美元。这就是一个极其标准的「微观结构信号」。它是具体的(5 万美元)、有方向的(他买的那个选项)、且可重复的(你可以回测他过去所有的下注记录)。
理解了什么是信号,我们再来看下一个问题:你的信号到底有多准?
1.2 什么是 IC?你的信号的「成绩单」
每一个做过交易的人,都经历过这种时刻:你的分析明明是对的,价格也确实往你预测的方向走了,但你最后还是亏钱了。
这不是运气问题。当你只依赖单一信号进行交易时,亏钱几乎是数学上的必然。理解为什么会这样,是接下来所有内容的基础。
在量化研究中,每一个信号都有一个衡量准确度的指标,叫做信息系数(Information Coefficient,简称 IC)。
IC 测量的是你的预测和市场实际走势之间的相关性。你可以把它理解为你的信号的「成绩单」。
那 IC 到底是怎么算出来的?我们一步一步来看。
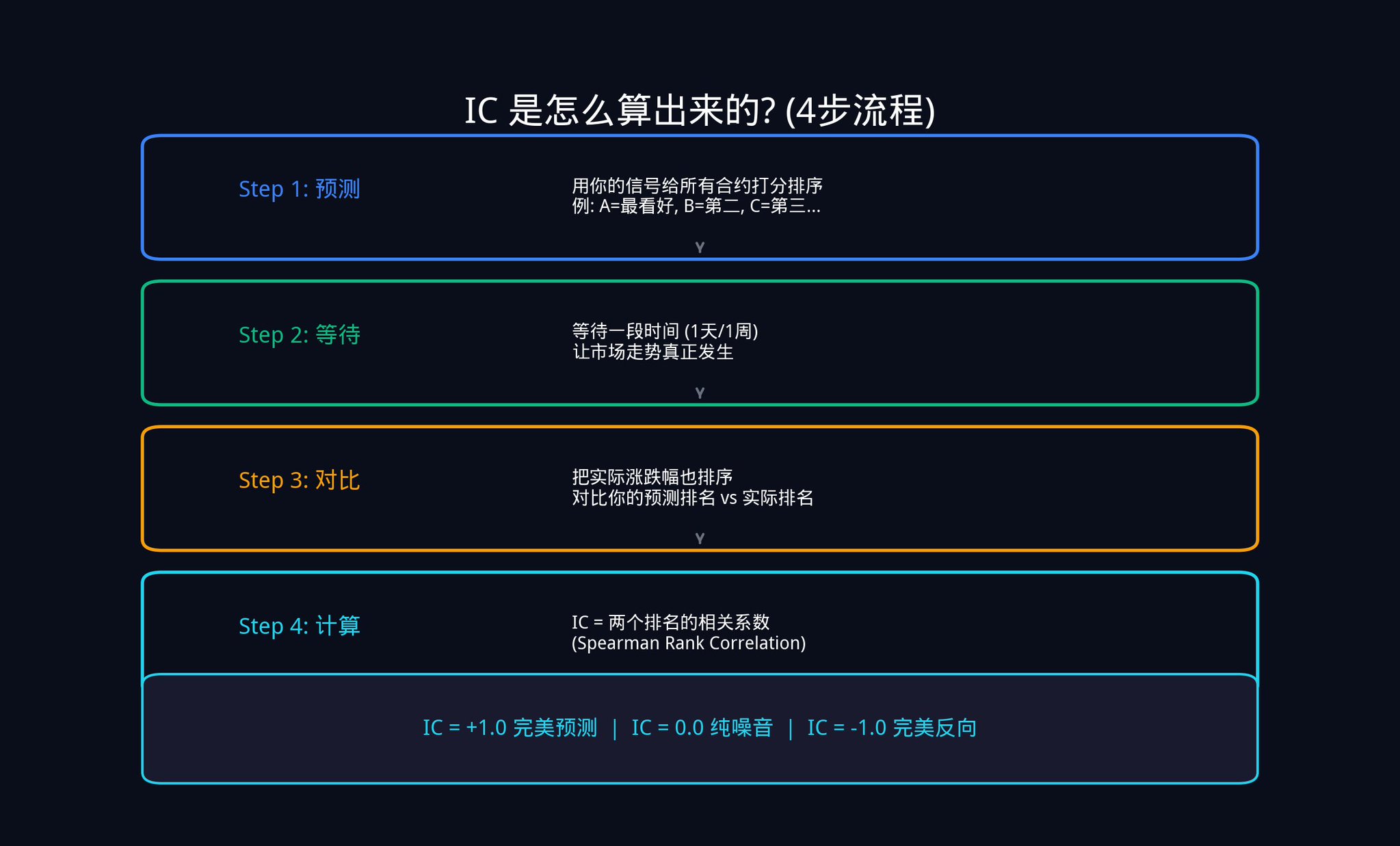
第一步,预测。 假设今天 Polymarket 上有 20 个活跃的合约。你用你的信号给这 20 个合约打分排序。你觉得合约 A 最可能涨,排第 1;合约 B 排第 2,以此类推,一直排到第 20。
第二步,等待。 等一天、一周,或者任何你设定的时间窗口,让市场走势真正发生。
第三步,对比。 时间到了之后,你把这 20 个合约的实际涨跌幅也排一个序。涨最多的排第 1,涨第二多的排第 2,以此类推。
第四步,计算。 现在你手上有两列排名:一列是你当初的预测排名,一列是实际结果排名。你要算的是这两列排名之间的相关性。
这里用到的是统计学中的 斯皮尔曼等级相关系数(Spearman Rank Correlation)。
听起来很吓人,其实逻辑很简单:
· 如果你预测排第 1 的合约,实际上也涨得最多;你预测排第 2 的,实际上也排第 2,那你的两列排名就高度一致,IC 就接近 +1.0。
· 如果完全相反(你说涨最多的反而跌最多),IC 就接近 -1.0。
· 如果毫无关系,IC 就是 0.0,说明你的信号跟掷骰子没有区别。
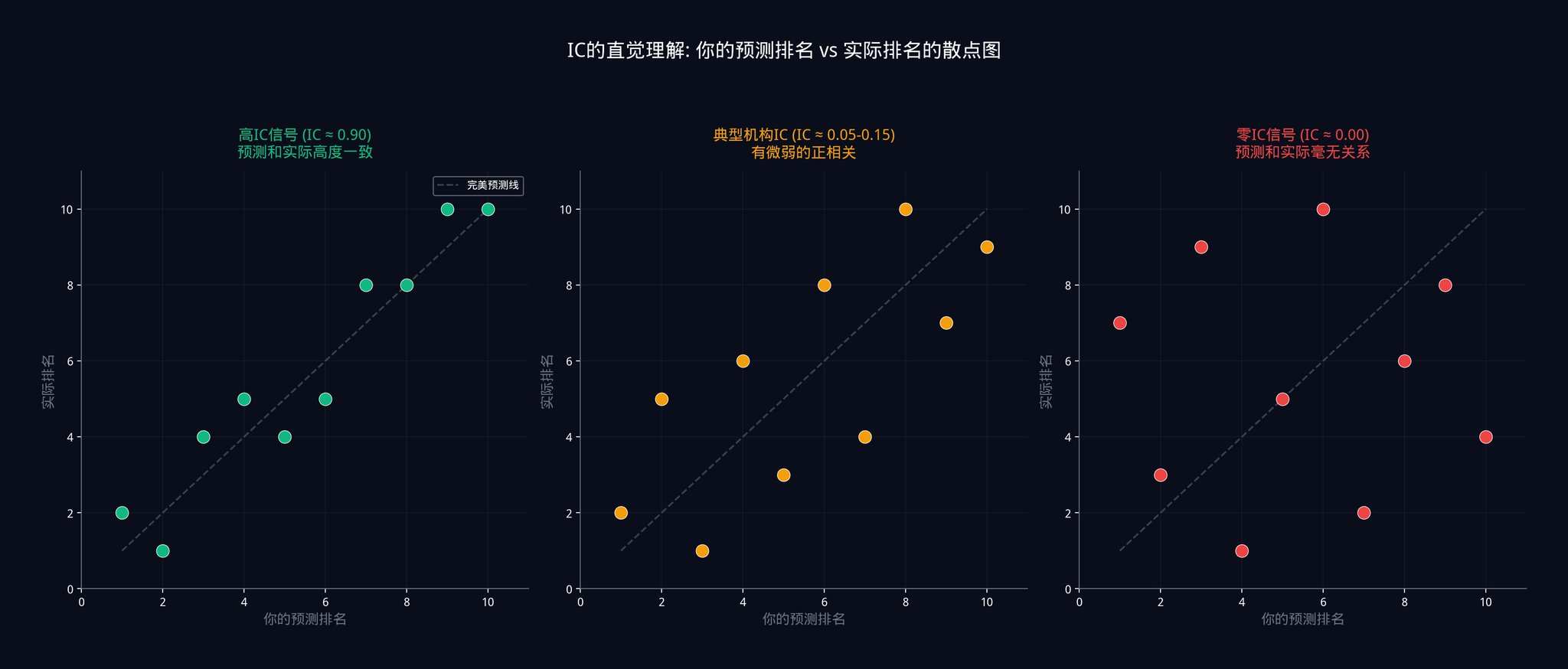
上面这张图展示了三种不同 IC 水平下,预测排名和实际排名之间的关系。
左边是 IC 接近 0.9 的情况,点几乎都落在对角线上,说明预测和实际高度一致。
中间是 IC 在 0.05 到 0.15 之间的情况,点散得到处都是,只有非常微弱的正相关趋势。
右边是 IC 等于 0 的情况,完全随机,没有任何规律。
为什么要用排名而不是直接用数值?
因为排名对异常值不敏感。假设某个合约因为黑天鹅事件暴涨了 500%,如果你用数值计算相关性,这一个异常点就会把整个结果带偏。但如果你用排名,它只是「排第 1」而已,不会对其他合约的排名产生影响。这就是为什么机构更喜欢用斯皮尔曼而不是皮尔逊相关系数。
在实际操作中,你不会只算一天的 IC。你会重复这个过程很多天(比如 100 天),然后取平均值。这个平均值就是你的信号的平均 IC。
那么,你猜猜华尔街顶级交易台,那些用着几十亿真金白银跑着的信号,IC 是多少?
答案是:0.05 到 0.15 之间。
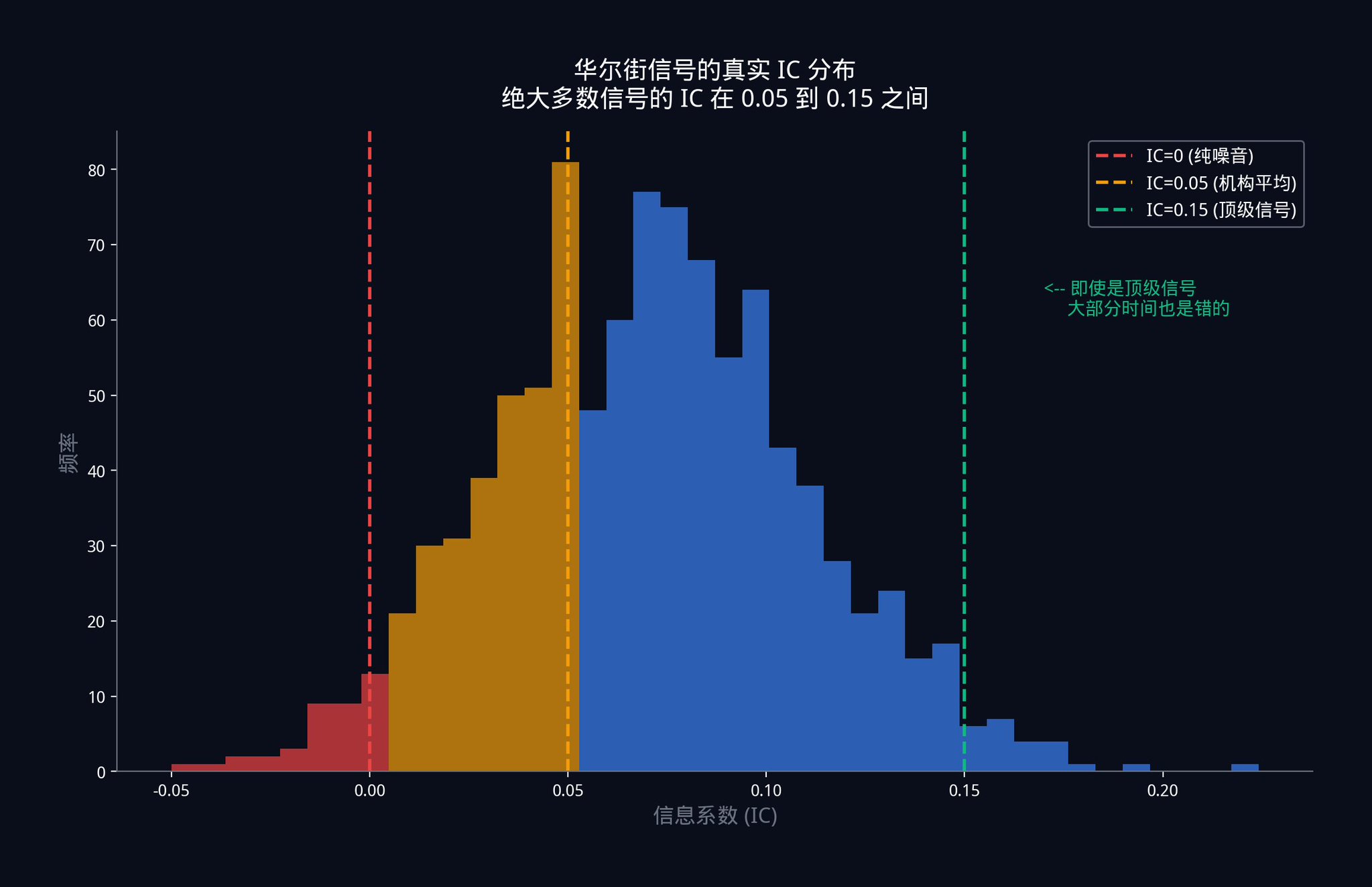
请你把这个数字再看一遍。机构级别使用的、最顶级的单一信号,在绝大多数时候都是错的。不是偶尔错,是大部分时间都在错。
IC = 0.05 意味着什么?
它意味着你的信号和市场实际走势之间只有 5% 的相关性。如果你画一张散点图,点几乎是随机分布的,只有非常非常微弱的正向趋势。
这并不是信号失效了。这是竞争性市场的本质。 任何强大的优势一旦被发现,资金就会疯狂涌入,直到这个优势被榨干、压缩到极低的水平。 在一个高效的市场里, 能稳定维持 0.05 的 IC,已经是非常了不起的成就了。
既然单个信号这么弱,机构到底是怎么赚钱的?
1.3 机构的杀手锏:主动管理基本定律
1994 年,两位量化研究先驱 Richard Grinold 和 Ronald Kahn 在他们的著作《Active Portfolio Management》中,提出了一个改变了整个资产管理行业的公式:
IR = IC x √N
这个公式被称为主动管理基本定律(The Fundamental Law of Active Management)。

所以,这三个字母分别代表什么?
IR(Information Ratio,信息比率) 是你整个交易系统的「综合成绩」。它衡量的是你每承担一单位风险,能赚到多少钱。你可以把它想象成一个「性价比」指标。IR 越高,说明你的策略越「稳」。在量化界,IR 达到 1.0 就已经被认为是顶级水平了。
IC(Information Coefficient,信息系数) 就是刚才花了一整节讲的东西:你单个信号的平均准确度。
N 是你组合的独立信号的数量。 请注意,这里的 「独立」 二字至关重要。我在第四部分会详细解释为什么。
现在,这个公式的核心信息是:整个系统的表现(IR)等于 单个信号的准确度(IC)乘以信号数量的平方根(√N)。
那么,问题来了。为什么是平方根?为什么不是直接乘以 N?这个问题非常关键,我来帮你从零推导一遍。
想象你在抛硬币。每次正面朝上你赢 1 块钱,反面朝上你输 1 块钱。
如果你只抛 1 次,结果完全是随机的。你要么赢 1 块,要么输 1 块。
但如果你抛 100 次呢?你的总收益的期望值是 0(因为正反各 50 次)。但关键在于波动率。 统计学告诉我们,100 次独立抛硬币的总波动率不是 100,而是 √100 = 10。
为什么?因为独立的随机事件叠加在一起时,它们的噪音会互相抵消一部分。正面和反面会交替出现,不会全部朝一个方向走。所以总的波动增长得比总的次数要慢。
现在把这个逻辑套到信号组合上。假设你有 N 个独立信号,每个信号都有微小的正向优势(IC 大于 0)。
你的总收益(所有信号的优势加在一起)会随着 N 线性增长。因为每多一个信号,就多一份微小的优势。10 个信号的总优势是 1 个信号的 10 倍。
但你的总风险(所有信号的噪音叠加在一起)只会随着 √N 增长。因为独立的噪音会互相抵消。10 个独立信号的总噪音不是 1 个信号的 10 倍,而是大约 3.16 倍(√10 ≈ 3.16)。
所以,你的信息比率 = 总收益 / 总风险 = (IC x N) / (σ x √N) = IC x (N / √N) = IC x √N。
这就是 IR = IC x √N 的由来。
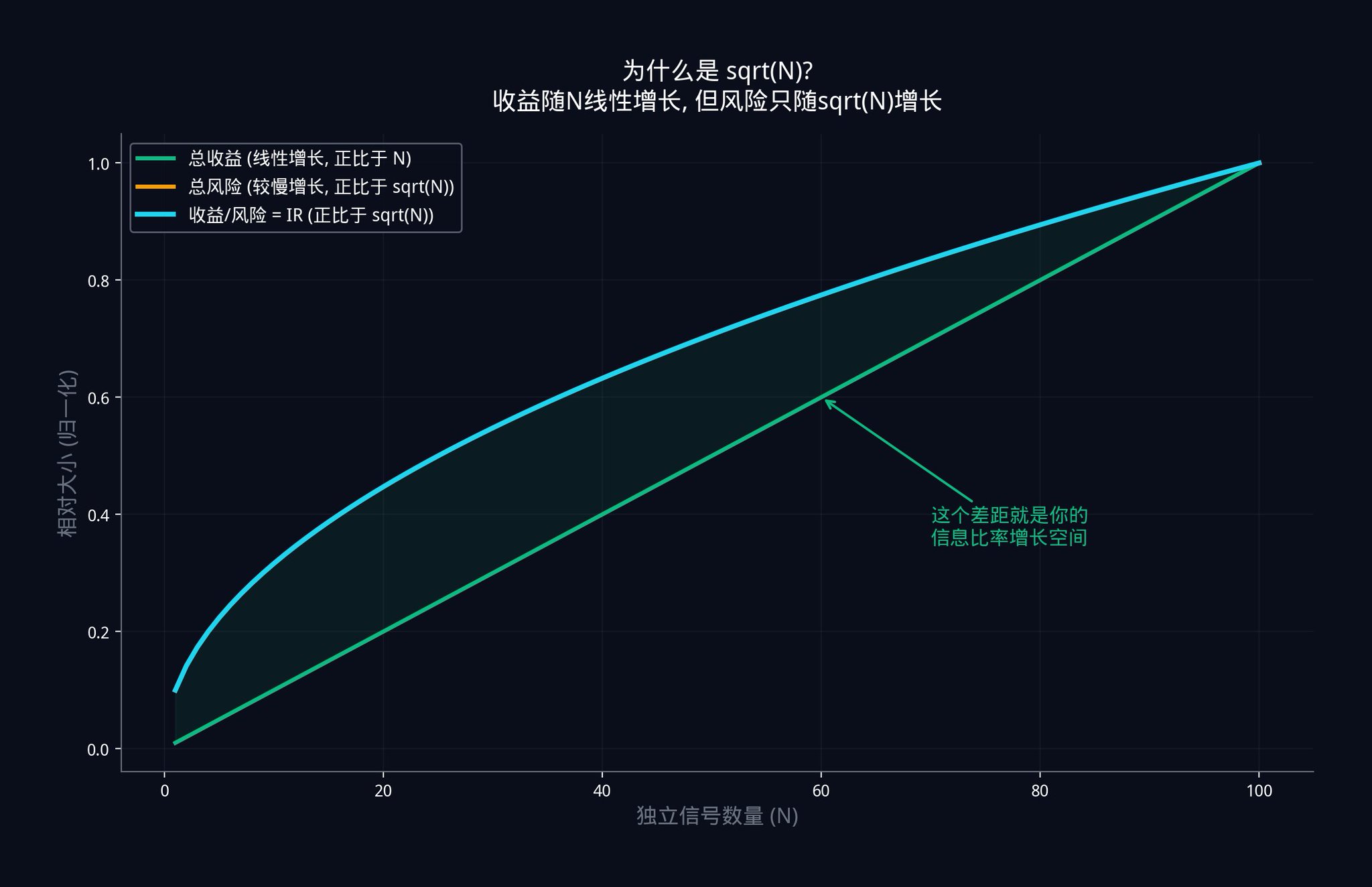
上图展示了这个关系。绿色的线是总收益,它随着信号数量线性增长。蓝色的线是信息比率 IR,它随着 √N 增长。收益在涨,风险也在涨,但收益涨得比风险快。两条线之间的差距越来越大。 这个差距,就是你通过增加独立信号获得的交易优势。
让我们来算一笔具体的账,感受一下这个公式的威力。
· 场景 A: 你有 50 个弱信号。每个信号都非常弱,IC 只有 0.05。那么你组合后的系统 IR = 0.05 x √50 = 0.05 x 7.07 = 0.354。
· 场景 B: 另一个交易员有 1 个强信号。他苦苦寻觅,终于找到了一个非常强大的单一信号,IC 高达 0.10(是你的两倍准)。但他只有一个信号,所以他的 IR = 0.10 x √1 = 0.10。
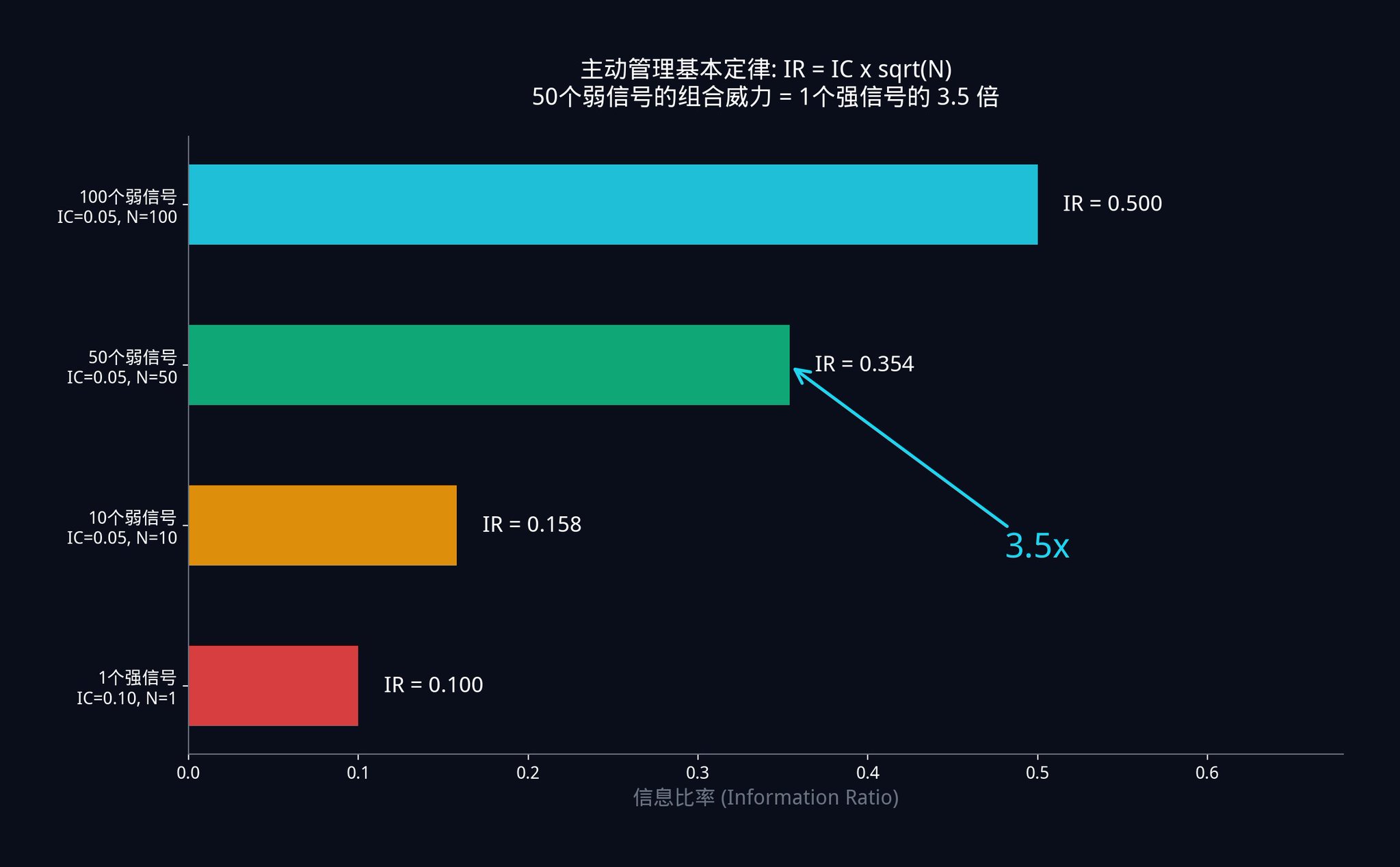
你用 50 个准确率只有他一半的「垃圾信号」,组合出来的系统表现,是他那个「神级信号」的 3.5 倍。
这就是为什么对冲基金宁愿雇佣几百个研究员去挖掘几百个微弱的信号,也绝对不会把所有赌注押在一个「完美指标」上。数学已经证明了,寻找完美信号是一条死路。
正确的方向是:收集尽可能多的独立弱信号,然后用数学把它们组合起来。
这个思路其实也是我们做 insiders.bot 钱包筛选器时的核心灵感。与其让用户去找一个「完美的聪明钱钱包」,不如帮用户同时追踪几百个策略不同,看的方向也不同的高胜率钱包,把这些弱信号叠加起来,才能实现真正准确的结论
进阶练习 1:
诚实地评估一下你现在最依赖的那个交易信号。它的 IC 是多少?如果你从来没有系统地测量过它,说明你一直在盲飞。
动手试试,用 Python 写一个简单的回测脚本。记录你过去 30 天的预测排名和实际结果排名,然后用 scipy.stats.spearmanr() 函数计算你的 IC。你可能会对结果感到震惊。
如果你想打好概率论的基础,推荐哈佛大学免费的 Introduction to Probability,前 6 章就够了。
理解了为什么要组合信号,下一步就是搞清楚:去哪里找这些信号?
第二部分:五大信号原材料
在第一部分,我们已经定义了什么是信号(可量化、有方向、可重复的数据点)。
但一个信号不需要很强。它只需要在大量观察中,表现得比抛硬币稍微准那么一点点,并且这种「稍微准一点」是稳定的、可验证的。
那么,机构到底去哪里找这些「稍微准一点」的数据点?
以下是系统化交易台真正在使用的五大核心信号类别。

2.1 价格与动量信号
动量信号看的是过去一段时间内,价格往哪走、走得多快。
为什么动量信号有效?因为市场参与者对新信息的反应是有惯性的。
· 短期内, 大家反应不够快,导致趋势会延续。
· 中期, 大家又容易反应过度,导致价格回调。
想象一辆正在加速的火车。即使司机松开了油门,火车不会立刻停下来。由于惯性,它还会往前冲一段距离。动量信号捕捉的就是这段「惯性距离」。
在 Polymarket 上怎么用?
假设一个合约的价格在过去 3 天内从 $0.40 稳步上涨到 $0.55,而且成交量也在同步放大。这说明有持续的买压在推动价格。
短期内价格继续上涨的概率就比较高。不是因为你知道什么内幕, 而是因为市场的惯性还没有消耗完。
在量化研究中,最基础的动量公式就是计算过去 d 天的平均回报:E(i) = (1/d) x Σ R(i,s)。d 是你选择的回看天数,R(i,s) 是合约 i 在第 s 天的回报。
2.2 均值回归信号
均值回归信号衡量的是一个资产偏离其「合理价值」有多远。
它的核心逻辑是:相关联的资产之间,价格比例应该是稳定的。当这种关系被打破时,回归的力量就会把它拉回来。
举个 Polymarket 上的例子。假设有两个合约:「特朗普赢得大选」和「共和党赢得大选」。通常情况下,这两个概率应该是高度绑定的(因为特朗普是共和党候选人)。如果某天「特朗普赢」的概率暴跌了 10 个百分点,但「共和党赢」的概率只跌了 2 个百分点,这就是一个强烈的均值回归信号。市场定价出错了,它们迟早会重新对齐。
均值回归信号就像一根橡皮筋。你把它拉得越远,它弹回来的力量就越大。但要注意,橡皮筋也有被拉断的时候。所以均值回归信号需要配合其他信号一起使用,而不是单独依赖。
2.3 波动率信号
波动率信号看的是隐含波动率(市场预期的波动幅度)和已实现波动率(实际发生的波动幅度)之间的差距。
为什么会有这个差距?因为卖出波动率的人(比如卖期权的人)承担了巨大的尾部风险。他们需要额外的补偿来覆盖那些极端情况。这就像保险公司收取的保费总是高于实际赔付的期望值一样。
在 Polymarket 上,波动率信号可以这样理解:如果一个合约的价格在 $0.45 到 $0.55 之间剧烈波动,但基本面并没有发生任何实质性变化(没有新的新闻、没有政策变动),那么这种「虚假的波动」本身就是一个信号。它告诉你市场参与者在恐慌或兴奋,但这种情绪往往是过度的,价格最终会回到合理水平。
2.4 因子信号
因子信号是经过几十年学术研究证实的、系统性的收益溢价。 最著名的五个因子包括:
· 价值(Value)
· 动量(Momentum)
· 低波动(Low Volatility)
· 套息(Carry)
· 质量(Quality)
每一个因子,都代表了市场在给风险定价时,人类行为或市场结构上的一种持续性缺陷。
比如「价值因子」之所以有效,是因为人类天生喜欢追逐热门的东西。大家都在讨论的合约,往往已经被定价充分了。而那些没人关注的「冷门合约」,反而更容易存在定价偏差。
在 Polymarket 上,这意味着你应该花更多时间研究那些交易量不大、但基本面有变化的合约,而不是去追那些已经被几千人盯着的热门盘口。这也是为什么我们在 insiders.bot 的首页,就加了波动率,最新市场,交易量,交易人数等等 方便用户找到这些有着潜在 Alpha 的市场的指标。
2.5 微观结构信号
微观结构信号是高频交易员的最爱。它看的是订单簿的深度失衡、买卖价差的动态变化,以及成交量的攻击性。
这些信号的生效时间极短,通常在几分钟到几小时之间。但它们能告诉你一件极其重要的事情:在价格真正移动之前,那些拥有信息优势的聪明钱正在哪里建仓。
衡量微观结构最常用的指标之一是有效价差(Effective Spread):
Effective Spread = 2 x |成交价 - 中间价|
有效价差越大,说明市场的流动性越差,交易成本越高。当有效价差突然扩大时,往往意味着有知情交易者正在进场,做市商为了保护自己而拉大了价差。
另一个关键指标是 VPIN(Volume-Synchronized Probability of Informed Trading,成交量同步知情交易概率)。这个指标由 Easley、Lopez de Prado 和 O'Hara 三位教授在 2012 年提出。它通过分析买卖成交量的不平衡程度,来估计市场中有多少交易是由「知情交易者」驱动的。
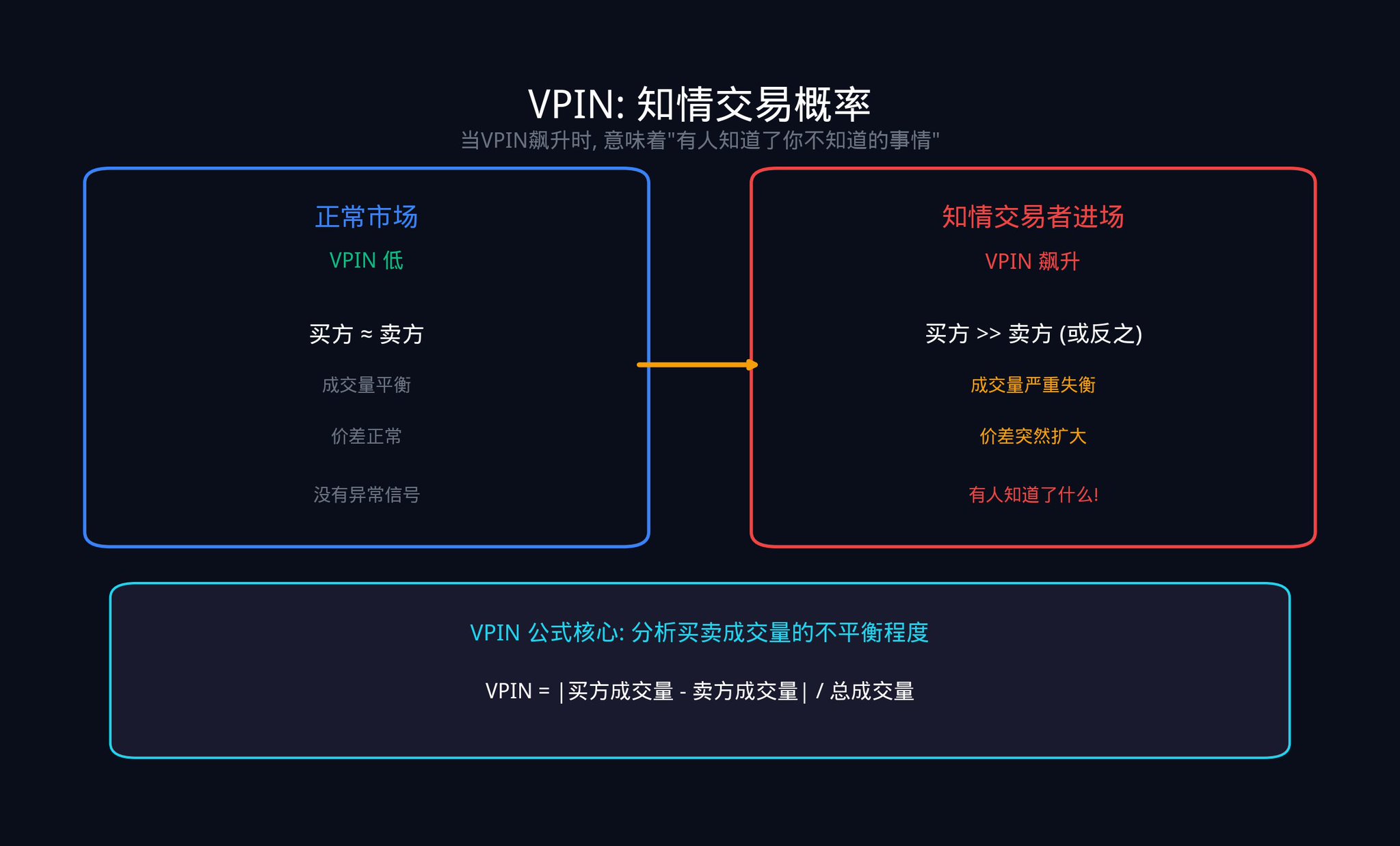
VPIN 的计算逻辑其实很直观:把成交量切成固定大小的「桶」(比如每 1000 笔交易一个桶),然后看每个桶里买方成交量和卖方成交量的差距有多大。 如果差距很大,说明有一方在单方面猛攻,这通常意味着知情交易者在行动。
当 VPIN 突然飙升时,往往意味着有人知道了你不知道的事情。2010 年的「闪电崩盘」(Flash Crash)发生前几个小时,VPIN 就已经开始异常飙升了。
在 Polymarket 上,聪明钱的链上行为就是最直接的微观结构信号。当一个历史胜率超过 65% 的钱包突然在某个合约上下了一笔大额注单,这就是一个非常有价值的信号。
我们在 insiders.bot 的聪明钱浏览器和 v1.2/v1.3 信号里做的事情,本质上就是把这种链上的微观结构信号实时推送给你。
记住,这五类信号中的任何一个,单拿出来都不足以形成系统性的优势。它们只是原材料。
接下来,我们要进入最核心的第三部分:那台把原材料变成黄金的「组合引擎」。
第三部分:11 步组合引擎
这是整篇文章最硬核的部分。这 11 个步骤,是机构用来把一堆原始信号转换成一个最优权重组合的完整程序。
这 11 步可以拆解为四个阶段: 数据准备、消除市场噪音、提取独立优势、分配最终权重。
先重新说一下大背景:假设你有 N 个信号 (比如 50 个)。每个信号在过去一段时间内都产生了 一系列回报数据 (也就是每天赚了多少或亏了多少)。
这个组合系统要做的事情,就是根据这些历史数据,算出每个信号应该分配多少资金权重。
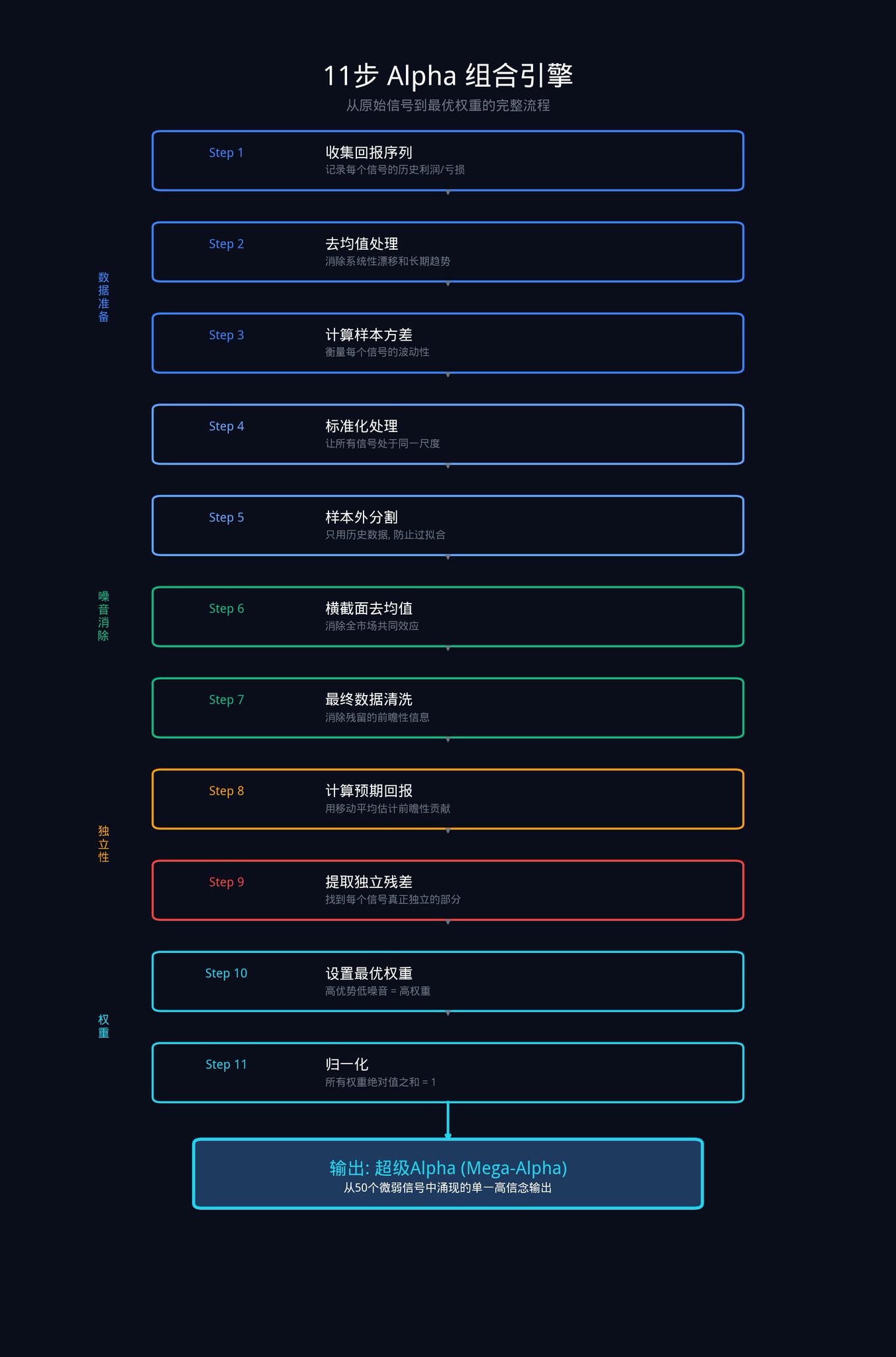
阶段一:数据准备
这个阶段的目标是让所有信号站在同一起跑线上。
第 1 步:收集每个信号的历史表现
这是最基础的一步。你需要记录每个信号在过去每个时间段内的实际利润或亏损。
比如,你的动量信号在过去 30 天里,第 1 天赚了 2%,第 2 天亏了 1%,第 3 天赚了 0.5%...... 把这些数据全部记录下来。每个信号都有这样一列数据。
用数学语言来说,就是收集每个信号 i 在每个时间段 s 的回报 R(i,s)。
第 2 步:消除系统性漂移(去均值)
把每个信号的历史回报,减去它自己的平均回报。
为什么要这么做?
举个例子。
· 假设你有一个「逢低买入」的信号。过去一年整个加密市场都在大涨,所以这个信号看起来赚了很多钱。
· 但这真的是信号的功劳吗?不一定。可能换成随便一个策略,在牛市里都能赚钱。减去平均值之后,你才能看到这个信号在「排除了市场整体趋势」之后,到底有没有真正的预测能力。
具体公式 : X(i,s) = R(i,s) - mean(R(i))。
第 3 步:计算每个信号的波动率
这一步衡量的是每个信号的回报有多大的波动性。
· 一个信号可能平均每天赚 0.1% ,但有时候赚 5% ,有时候亏 4% 。
· 另一个信号也是平均每天赚 0.1%, 但波动范围只在 -0.5% 到 +0.7% 之间 。
· 虽然两个信号的平均回报一样, 但第二个信号明显更「稳」,更值得信赖。
波动率就是用来量化这种「稳定程度」的。
具体公式:σ(i)² = (1/M) x Σ X(i,s)²。
第 4 步:标准化处理
把第 2 步的结果除以第 3 步的波动率。
为什么需要这一步?因为不同信号的「单位」不同。动量信号可能是按百分比计算的,微观结构信号可能是按基点(0.01%)计算的,波动率信号可能是按绝对数值计算的。如果你直接把它们放在一起比较,就像拿苹果和橘子比大小,毫无意义。
标准化之后,所有信号都被拉到了同一个尺度上。就像把美元、欧元、日元都换算成了同一种货币,这样才能公平地比较。
具体公式:Y(i,s) = X(i,s) / σ(i)。
阶段二:消除市场噪音
这个阶段的目标是把「市场整体的涨跌」从每个信号的表现中剥离出来,只留下信号自身的真正能力。
第 5 步:样本外分割
在计算权重时,只使用历史数据,丢弃最近的观察值。
这一步是为了防止「过度拟合」。
什么是过度拟合?打个比方,一个学生把过去十年的考试真题全部背了下来,模拟考试次次满分。但一到真正的考试,换了新题,他就完全不会做了。他不是在「理解知识」,而是在「背答案」。
在量化交易中,过度拟合的危害更大。 你的模型可能在历史数据上表现完美,但一到实盘就拉胯。 样本外分割就是确保你的模型是在「学习规律」,而不是在「记忆历史」。
具体做法是:
把你的数据分成两部分。
· 用前 80% 的数据来训练模型(计算权重),
· 用后 20% 的数据来验证模型是否真的有效。
· 如果模型在后 20% 的数据上也能赚钱,说明它学到了真正的规律。
第 6 步:横截面去均值(Cross-sectional Demeaning)
在每一个时间点,把每个信号的表现,减去所有信号在那个时间点的平均表现。
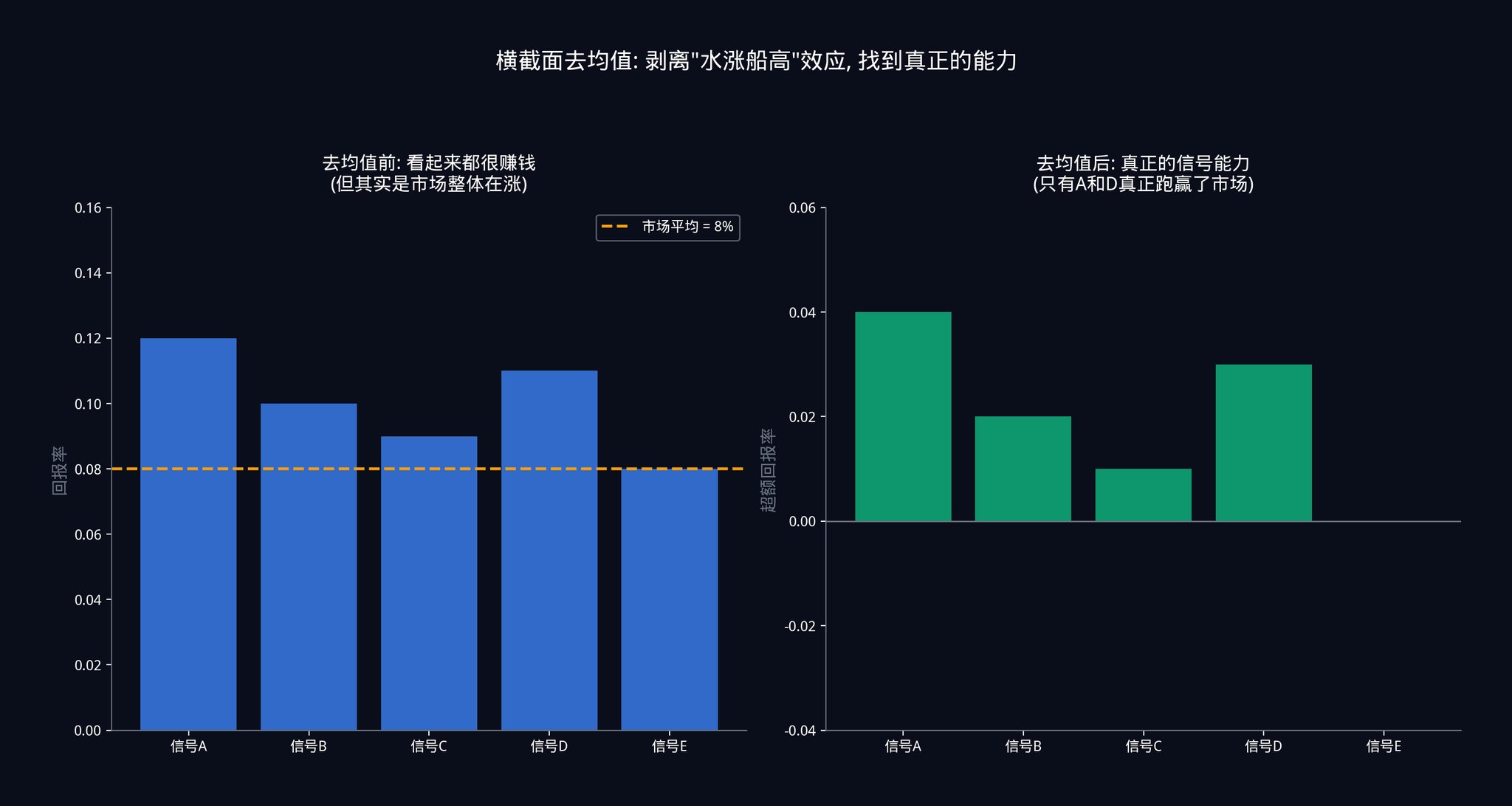
这一步非常关键,这里用一个具体的场景来解释。
假设今天美联储突然宣布降息。整个市场暴涨。你的 50 个信号可能同时发出了「买入」指令,而且每个信号看起来都赚了钱。
如果你不做横截面去均值 ,你会以为这 50 个信号都很准。 但实际上,这只是「水涨船高」的效应。市场整体在涨,你的信号不管怎么预测都能赚钱。 这不是信号的能力,而是市场的恩赐。
减去所有信号的平均表现之后,你才能看清真相:在大家都赚钱的日子里,到底哪个信号赚得比别人更多?在大家都亏钱的日子里,哪个信号亏得比别人少?这种「相对表现」,才是信号真正的能力。
更具体的说:Λ(i,s) = Y(i,s) - (1/N) x Σ Y(j,s)。
*注意,第 2 步的「去均值」和第 6 步的「横截面去均值」是不同的。第 2 步是对每个信号自己的时间序列去均值(消除长期趋势)。第 6 步是在每个时间点上,对所有信号之间去均值(消除市场整体效应)。两者缺一不可。
第 7 步:最终数据清洗
这是一个最终的数据卫生步骤。它确保在你的数据序列中,没有残留任何「前瞻性信息」。
什么是前瞻性信息?就是你在做决策的那个时间点上,不可能知道的未来数据。比如,你不能在周一用周五的收盘价来做决策。这听起来像是常识,但在复杂的数据处理流程中,这种「数据泄露」比你想象的更容易发生。
阶段三:提取独立优势
这个阶段是整个引擎的灵魂。它要做的事情是:从每个信号中,提取出它独一无二的预测能力,剔除掉它和其他信号重复的部分。
第 8 步:计算预期回报
使用移动平均线,计算每个信号在未来的预期贡献。
具体来说,就是取每个信号最近 d 天的平均回报,作为它未来表现的预测。然后把这个预测值标准化(除以波动率),让不同信号的预期回报可以直接比较。
公式上来说:
· E(i) = (1/d) x Σ R(i,s)
· E_norm(i) = E(i) / σ(i)。
第 9 步:提取独立残差(Orthogonalization,正交化)
这是整个 11 步中最关键的一步。
假设你有两个信号。
· 信号 A 是「看天气预报」
· 信号 B 是「看路人有没有带伞」。
这两个信号都能预测今天会不会下雨。
但问题是,路人带伞很可能也是因为看了天气预报。 所以信号 A 和信号 B 之间有大量的信息重叠。 如果你同时使用它们, 你以为你有两个独立的信号,但实际上你只有一个信号(天气预报)被表达了两次。
第 9 步做的事情,就是把这种信息重叠剔除掉。
具体怎么做?对每个信号的预期回报 E_norm(i),用其他所有信号的历史数据 Λ(i,s) 做一个回归分析。回归的意思是:用其他信号来「解释」这个信号。能被解释的部分,就是重叠的部分,扔掉。解释不了的部分,就是这个信号独一无二的贡献,保留。
这个「解释不了的部分」,在数学上叫做残差(Residual),记作 ε(i)。
如果你学过线性代数,这就是 Gram-Schmidt 正交化的一个应用。如果你没学过也没关系,你只需要记住一件事: 第 9 步是在找出每个信号真正独一无二的、不可替代的那部分预测能力。
阶段四:分配最终权重
第 10 步:设置最优权重
权重的计算公式是:w(i) = η x ε(i) / σ(i)。
这个公式说的是:每个信号的权重,等于它的独立贡献 ε(i)(第 9 步算出来的),除以它的波动率 σ(i)(第 3 步算出来的),再乘以一个缩放系数 η。
这意味着什么?引擎会自动给那些 「独立贡献大」 且 「表现稳定」 的信号分配更高的权重。而那些「噪音大」或者「只会跟风」的信号,会被自动降权。
这一切都是数学自动完成的,不需要任何主观判断。你不需要凭感觉去决定「这个信号应该占多少比例」。公式会告诉你最优答案。
第 11 步:归一化
最后一步,调整 缩放系数 η ,使所有权重的绝对值之和等于 1。
这确保了你的总资金分配是 100%,不会在不知不觉中加上杠杆。 如果不做这一步,你可能会发现你的权重加起来是 150%,意味着你在用 1.5 倍杠杆交易,而你自己完全没有意识到。
用数学语言来说:设置 η 使得 Σ|w(i)| = 1。
这 11 步的最终输出,就是你的 N 个信号中每一个的最终权重。当你把这些微弱的信号按权重组合在一起时,你就得到了一个超级 Alpha(Mega-Alpha)。一个高胜率、高信念的单一输出。
进阶练习 2:
如果你在当前的信号堆栈上运行这个程序,你会对哪些信号获得了高权重、哪些获得了低权重感到惊讶吗?答案会告诉你,你对自己正在运行的东西的独立性结构了解得有多好。
如果你想深入理解这套矩阵运算背后的逻辑,强烈建议去看 MIT 免费公开课 Linear Algebra 中关于正交化的章节。Gilbert Strang 教授讲得非常清楚。
第四部分:独立性陷阱
组合引擎解决了一个问题。这个问题在你一次只看一个信号时是隐形的,但一旦你理解了数学,它就变得无处不在。
让我们回到第一部分提到的主动管理基本定律:
IR = IC x √N
还记得这三个字母代表什么吗?IR 是你整个系统的「风险调整后收益」(也就是你的策略有多稳)。IC 是你单个信号的平均准确度。N 是你组合的独立信号的数量。
现在我要强调一个很多人忽略的关键词:独立。
这里的 N,不是你信号堆栈中信号的总数。它是有效独立信号的数量。这两个数字可能差得非常远。
为什么?因为信号之间会「偷偷地」相互关联。
一个动量信号和一个均值回归信号,在性质上看起来是完全相反的(一个追涨,一个抄底)。但在某些市场环境下,两者可能在同一时间、同一方向对同一个宏观经济新闻做出反应。
· 比如,美联储突然加息,动量信号说「趋势向下,卖出」,均值回归信号也说「偏离均值太远了,但方向也是向下」。
· 在这个时刻,两个看似独立的信号,实际上在表达同一个观点。
如果你给它们相等的权重,你以为你在两个独立的观点之间分散了风险。但实际上, 你是在同一个观点上加了双倍的仓位。

这就是为什么第三部分中的第 6 步(横截面去均值,也就是在每个时间点上减去所有信号的平均表现,消除「水涨船高」效应)和第 9 步(提取独立残差,也就是通过回归分析剔除信号之间的信息重叠,只保留每个信号独一无二的贡献)如此重要。它们的作用就是识别并消除信号之间隐藏的共享成分。
运行 50 个相关的信号,可能只给你带来 10 到 15 个独立信号的分散化效果。 只有当你的信号建立在真正独立的信息源上,并且正确地运行了组合引擎,你才能获得全部 50 个信号的完整好处。
这在实际操作中意味着什么?
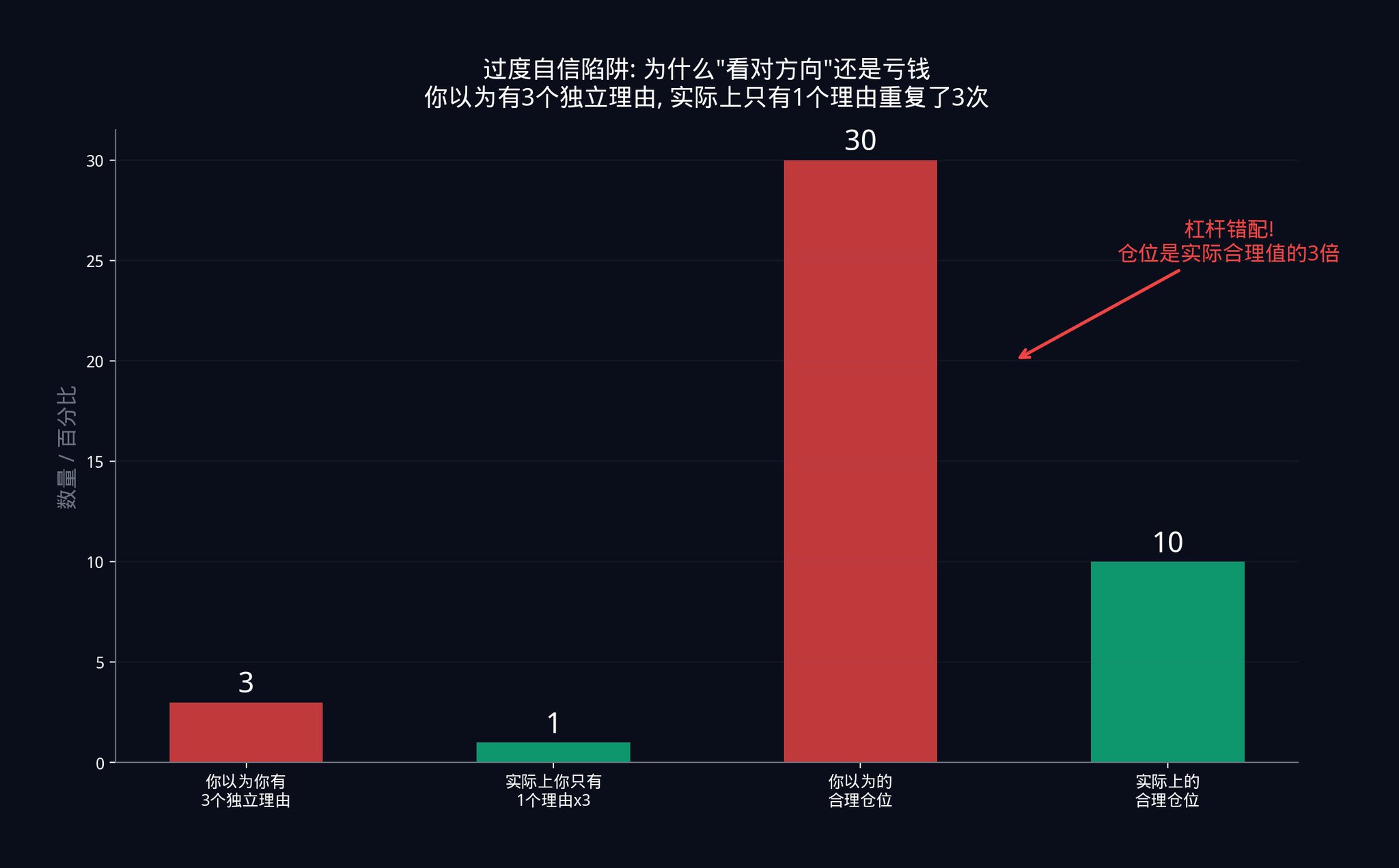
· 假设一个交易员认为自己在运行 20 个独立信号。他按照 20 个独立信号来计算仓位大小。但实际上,由于信号之间的隐藏相关性,他只有 6 个有效独立信号。
· 20 个独立信号支撑的仓位大小,对于 6 个信号来说太大了。大了多少?大了 20/6 ≈ 3.3 倍。他的实际杠杆是他以为的 3 倍多。
这种杠杆错配,是大多数系统化策略爆仓背后的真正原因。交易员在方向上是对的,但在规模上是错的。他看对了市场会涨,但他下的注太大了。一个正常的回调就足以把他清算出局。
组合引擎强制进行诚实的核算。它不会让你自欺欺人。它会告诉你,你的信号堆栈的真实独立性结构是什么样的。然后根据真实情况来分配权重,而不是根据你以为的情况。
那些在分析正确的交易上持续亏损的交易员,几乎总是输给了他们没有测量的相关性。他们以为自己有三个独立的理由感到自信。实际上他们只有一个理由被表达了三次。而仓位却是按三个理由来定的。
组合引擎从结构上消除了这种失败模式。
进阶练习 3:
拿出你现在正在使用的所有信号,两两配对,计算它们之间的相关系数。你可以用 Python 的 numpy.corrcoef() 函数。如果任何一对信号的 相关系数超过 0.5 ,那么它们在数学上就不是独立的。你需要重新审视你的信号堆栈。
推荐阅读 Marcos Lopez de Prado 的 Advances in Financial Machine Learning,特别是关于特征重要性和正交化的章节。这本书是现代量化方法的必读之作。
第五部分:在 Polymarket 上落地
前四个部分的所有内容,都是在股票和多资产系统化交易的背景下建立的。好消息是,这套数学可以直接迁移到预测市场。只需要做一个替换:你不是在组合关于「预期回报」的信号,而是在组合关于「预期概率」的信号。
在预测市场中,每个信号产生的不是一个回报估计,而是一个隐含概率估计。
5.1 五种概率信号
第一,跨平台定价信号: 如果 Polymarket 上某个合约的 YES 价格是 $0.45,但 Betfair 上同一个事件的赔率暗示概率是 52%,那么这 7 个百分点的价差就是你的信号。两个平台在给同一个事件定不同的价,至少有一个是错的。
第二,校准信号: 对 4 亿笔 Polymarket 历史交易的研究发现了一个系统性的偏差:定价在 5% 到 15% 之间的合约,最终解决为 YES 的比例只有 4% 到 9%。这意味着市场系统性地高估了低概率事件发生的可能性。 这个偏差是稳定的、可重复的,因此它是一个有效的信号。
第三,贝叶斯更新信号: 这是量化交易的灵魂工具。它回答的核心问题是:当你获得了新的数据,你应该如何精确地更新你原有的信念?
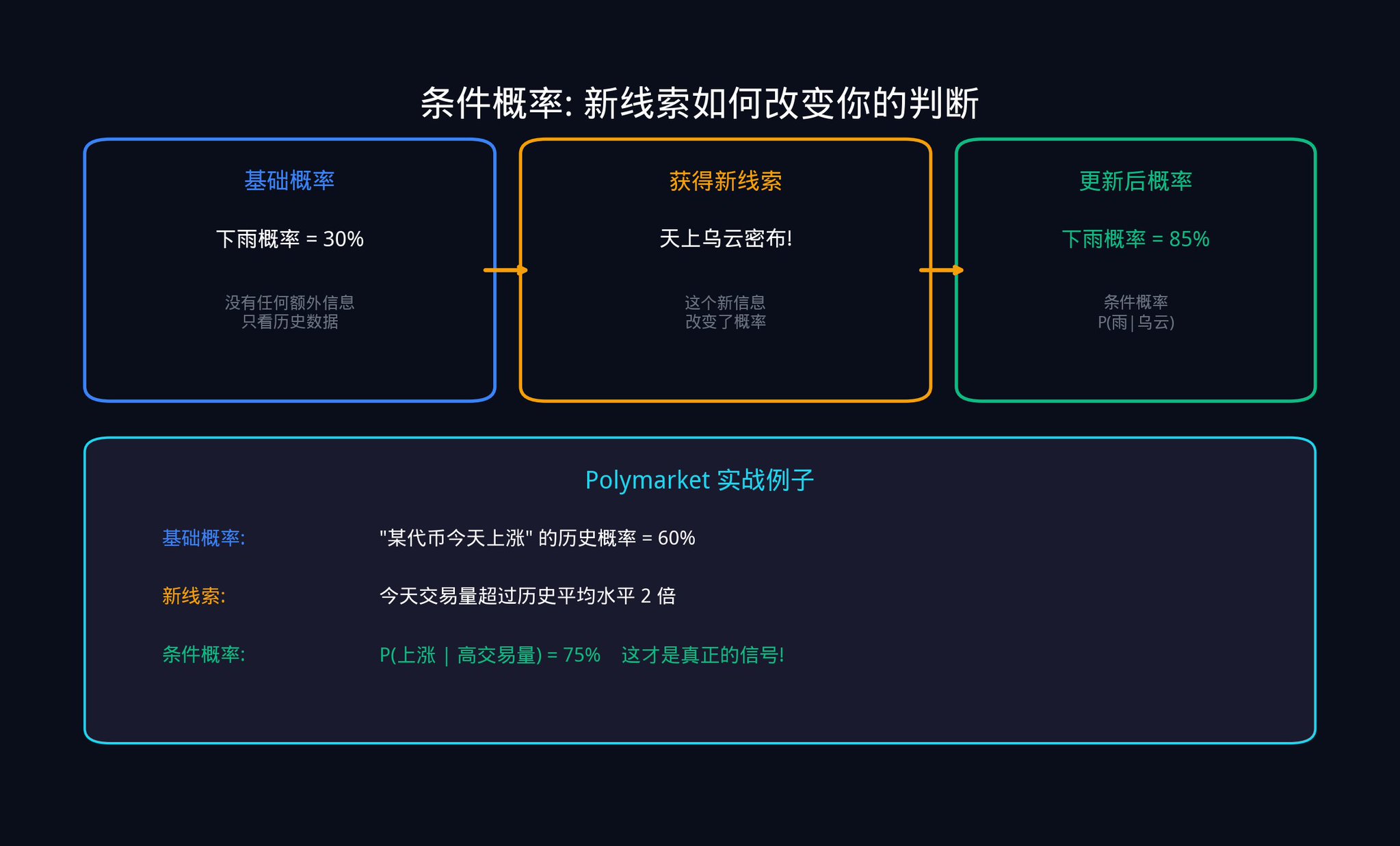
让我用一个具体的例子来解释贝叶斯更新。
假设你关注一个 Polymarket 合约:「某国会法案是否会在本月通过?」。目前市场价格是 $0.40,也就是市场认为通过的概率是 40%。这是你的先验概率(Prior)。
突然,一条新闻出来了:该法案获得了一位关键参议员的公开支持。
你不能直接把概率改成 80%。你需要用贝叶斯公式来精确计算。
贝叶斯公式是:
P(通过|支持) = P(支持|通过) x P(通过) / P(支持)
翻译成大白话就是:
「在已知这位参议员公开支持的情况下,法案通过的概率」=「如果法案真的会通过,这位参议员公开支持的概率」x「法案通过的先验概率」/「这位参议员公开支持的总概率」
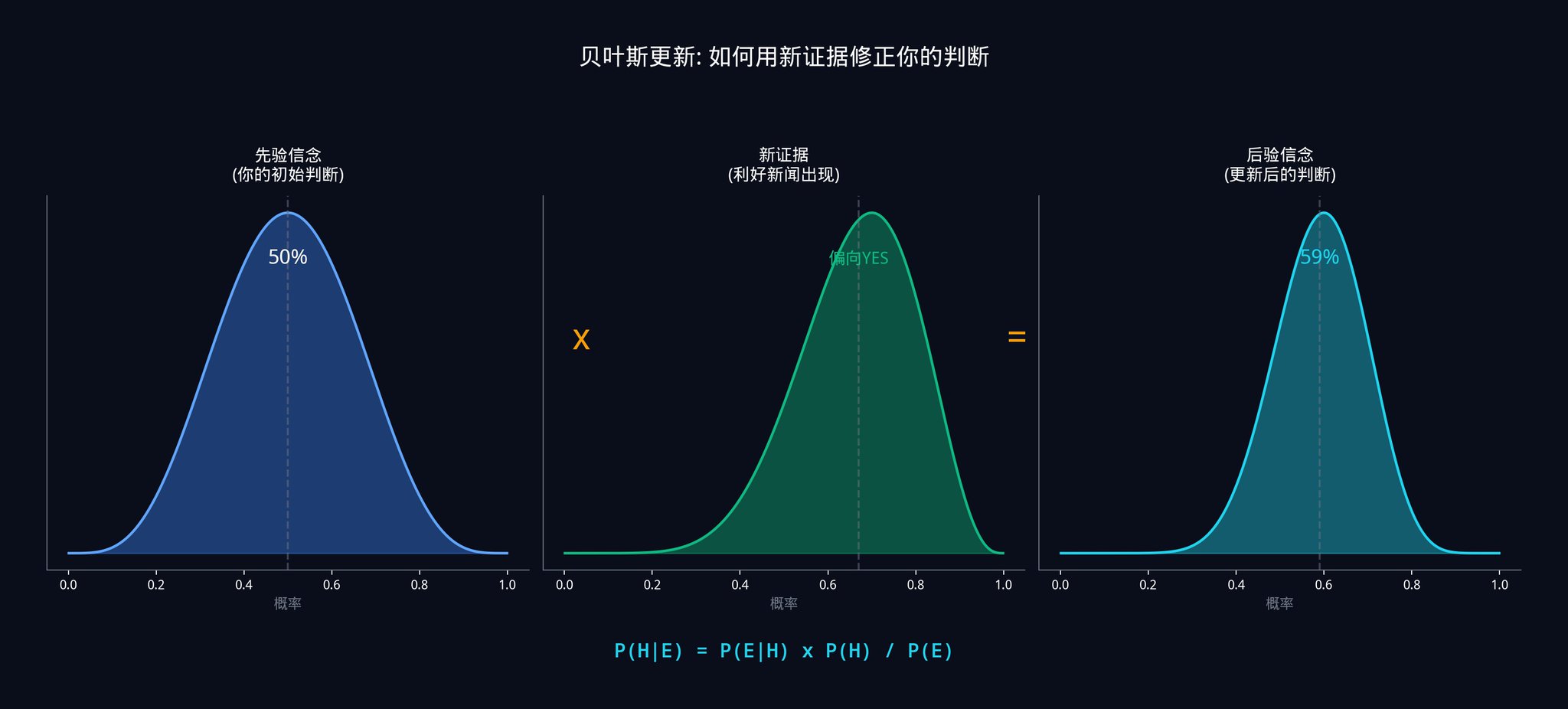
假设你估计:
· 如果法案真的会通过,这位参议员公开支持的概率是 80%(因为他通常会在有把握时才表态)
· 如果法案不会通过,这位参议员公开支持的概率是 20%(他偶尔也会站错队)
· 法案通过的先验概率是 40%
那么:
· P(支持) = 0.80 x 0.40 + 0.20 x 0.60 = 0.32 + 0.12 = 0.44
· P(通过|支持) = 0.80 x 0.40 / 0.44 = 0.32 / 0.44 = 72.7%
所以,在看到这条新闻之后,你应该把法案通过的概率从 40% 更新到 72.7%。如果市场价格还停留在 $0.50,你就有了一个 22.7% 的优势。
贝叶斯更新的精髓在于,你不是在「猜」一个新概率,而是在用数学精确地计算它。你的每一次判断都有据可依。
第四,微观结构信号: 使用 VPIN(我们在第二部分讲过的「知情交易概率」指标,它通过分析买卖成交量的不平衡程度来判断是否有知情交易者在行动)和有效价差,根据知情订单流的方向暗示一个概率。
第五,动量信号: 根据合约接近解决时的价格变动速率和方向暗示一个概率。
5.2 从信号到下注:完整流程
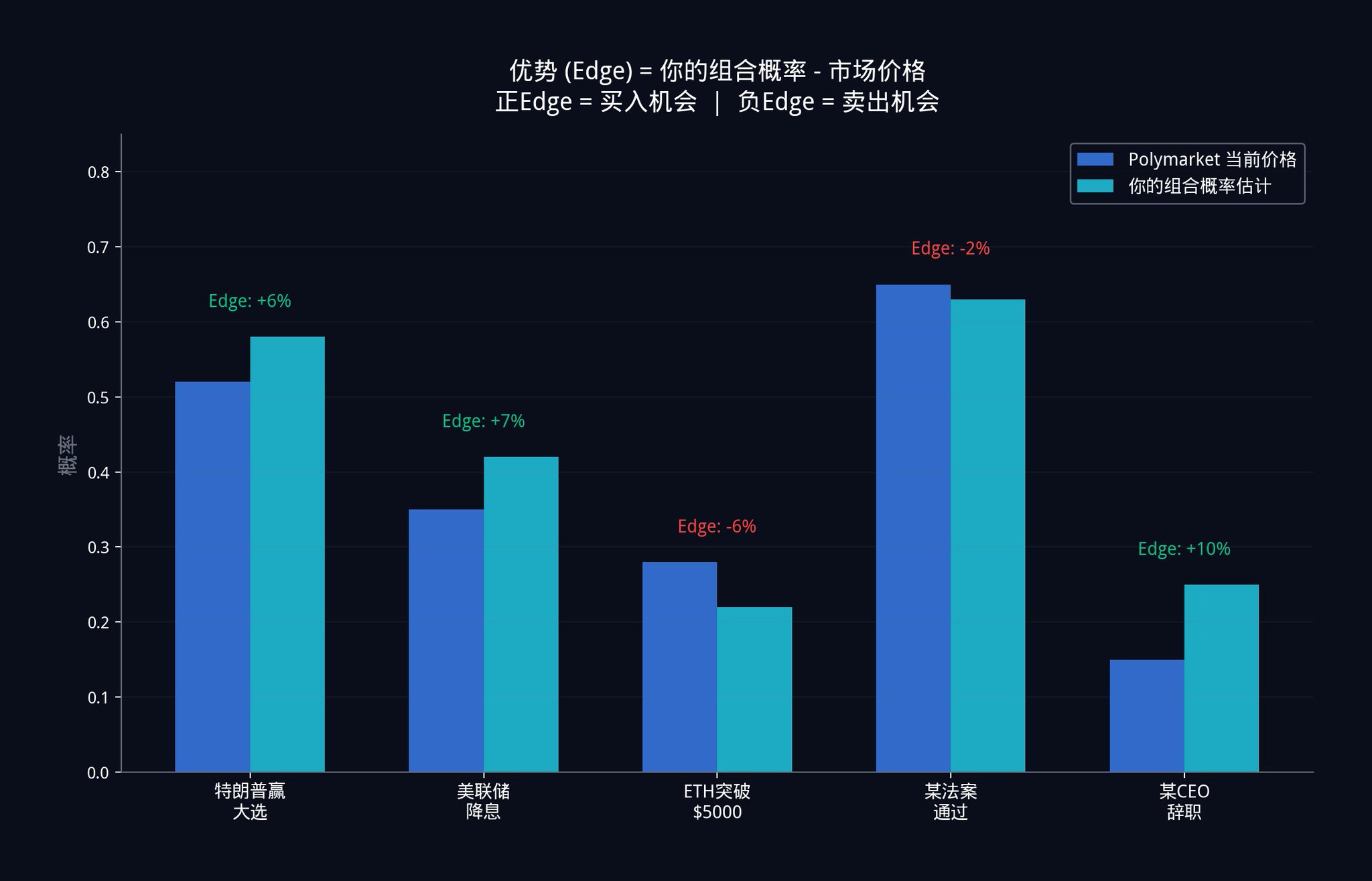
将这些隐含概率估计中的每一个,完全按照第三部分描述的 11 步组合引擎运行。输出是一个单一的加权组合概率估计。这个估计根据每个信号的独立贡献(还记得第 9 步的正交化吗?就是剔除信号之间的信息重叠,只保留独一无二的部分),分配了数学上最优的权重。
那个组合估计和当前 Polymarket 价格之间的差距,就是你的优势(Edge)。
5.3 凯利公式:你到底该下注多少?
有了优势之后,最重要的问题来了:你应该拿多少钱去下注?
下注太少,你浪费了优势,赚得不够多。下注太多,一次判断失误就可能让你回到原点。
机构使用的是凯利公式(Kelly Criterion)。标准的凯利公式是这样的:
f_kelly = (p x b - q) / b
其中 p 是你估计的胜率(你的组合概率),q = 1 - p 是败率,b 是赔率。
在 Polymarket 上,赔率 b 可以直接从价格算出来:b = (1 / 市场价格) - 1。比如市场价格是 $0.40,那么赔率 b = (1/0.40) - 1 = 1.5。
假设你的组合模型告诉你真实概率是 60%(也就是 p = 0.60),而市场价格是 $0.40(赔率 b = 1.5)。那么标准凯利建议你下注:
f_kelly = (0.60 x 1.5 - 0.40) / 1.5 = (0.90 - 0.40) / 1.5 = 0.50 / 1.5 = 33.3% 的资金。
但标准凯利有一个致命的假设:它假设你的胜率估计是 100% 准确的。在现实中,你的估计总会有误差。所以机构使用的是经验凯利公式,它加入了一个「不确定性惩罚」
f_empirical = f_kelly x (1 - CV_edge)
其中 CV_edge 是你的优势估计的变异系数(Coefficient of Variation)。它衡量的是你的估计有多不确定。CV_edge 越大,说明你越不确定,公式就会自动减少你的下注金额。
怎么计算 CV_edge?你可以用蒙特卡洛模拟。简单来说,就是用你的模型跑几千次模拟,看看你的优势估计在不同场景下会变化多少。变化越大,CV_edge 越高,你就应该下注越少。
接着上面的例子。如果你的 CV_edge = 0.3(也就是你的估计有 30% 的不确定性),那么经验凯利建议你下注:
f_empirical = 33.3% x (1 - 0.3) = 33.3% x 0.7 = 23.3% 的资金。
在实际操作中,很多机构甚至只下「半凯利」(Half-Kelly),也就是再除以 2,变成大约 12%。 因为长期来看,少赚一点远比爆仓好得多。
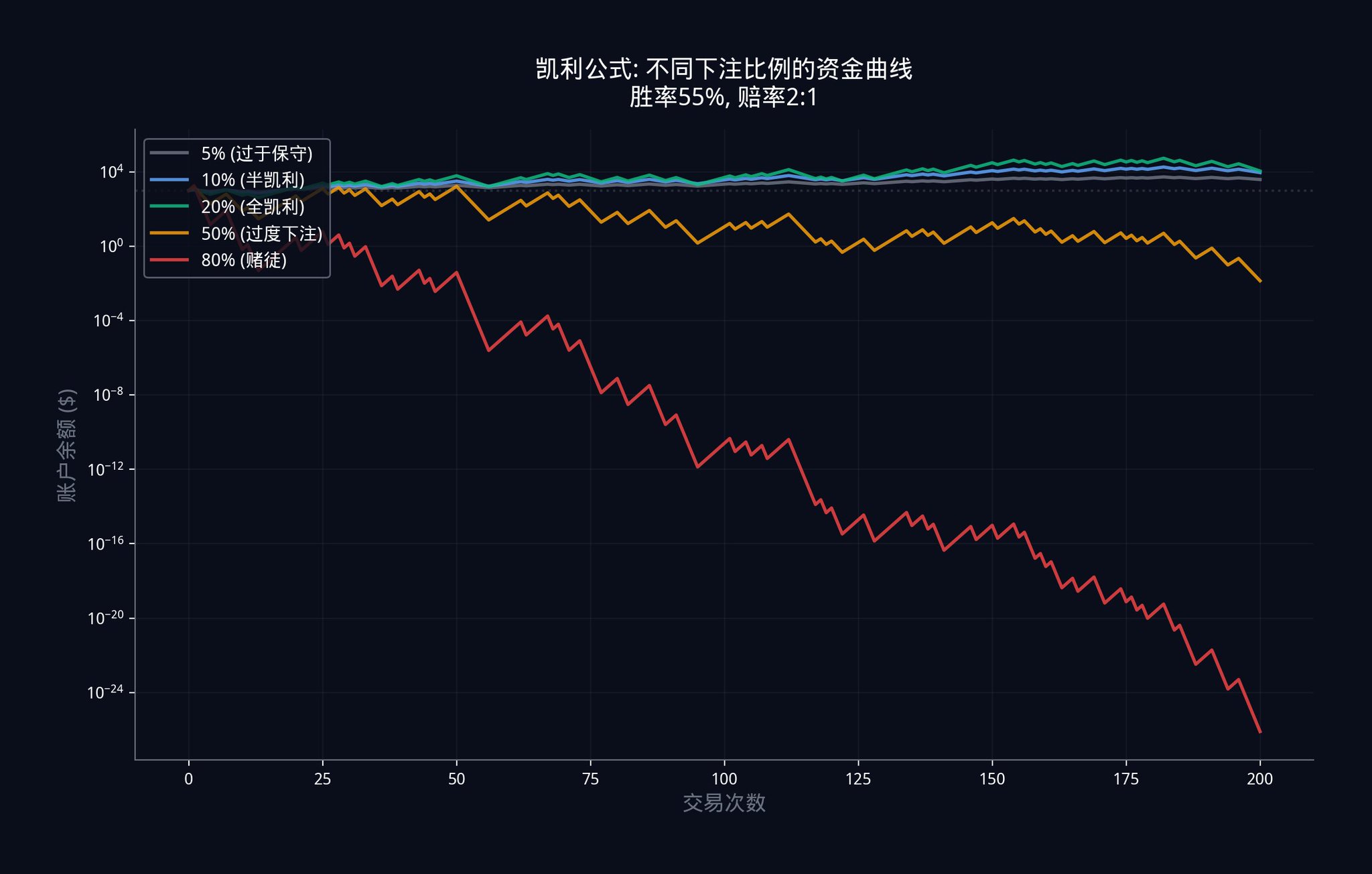
5.4 完整的 Polymarket 交易管道
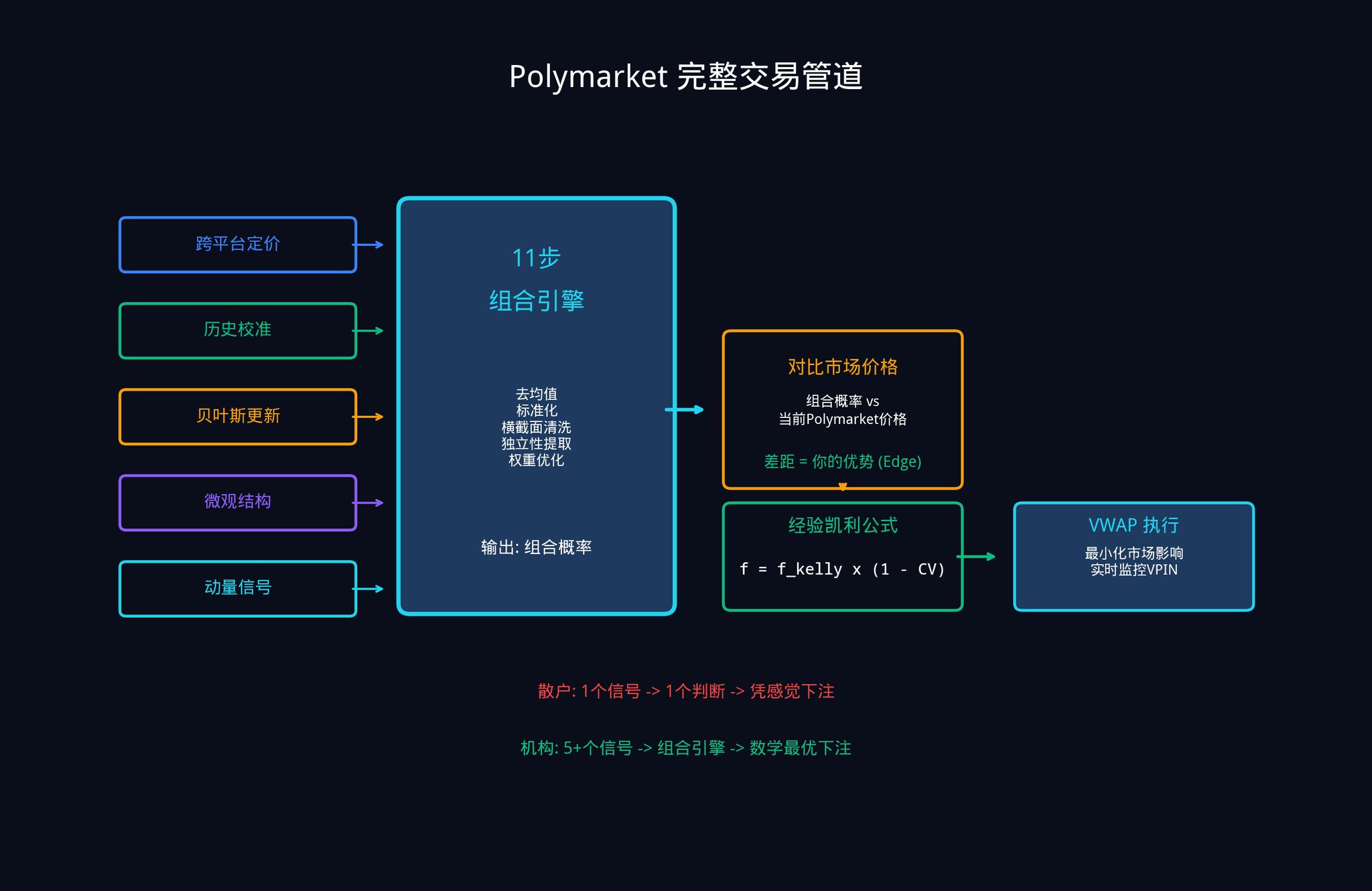
把所有东西串在一起,完整的工作流程是这样的:
1. 五个或更多输入信号,每个产生一个隐含概率估计
2. 通过 11 步组合引擎处理
3. 输出一个单一的加权组合概率
4. 与当前市场价格比较,计算你的优势(Edge)
5. 用经验凯利公式确定下注规模
6. 用 VWAP(成交量加权平均价格)优化执行,减少你的大额订单对市场价格的冲击
7. 实时监控 VPIN 变化,当知情交易者变得活跃时及时调整策略
这个框架对于预测市场特别有价值,原因很简单:你的绝大多数竞争对手,都在用单一模型、单一数据源、单一概率估计来交易。而你现在已经知道了如何把多个弱信号组合成一个强信号。这就是你的结构性优势。
进阶练习 4:
选择一个你关注的 Polymarket 合约。尝试从至少三个不同的角度(比如跨平台定价、历史校准、最近的新闻事件)分别估计它的概率。然后简单地取加权平均,看看你的组合估计和当前市场价格之间有没有差距。如
果有,恭喜你,你刚刚手动完成了一个简化版的 Alpha 组合。
推荐阅读 Edward Thorp 的 A Man for All Markets。Thorp 是凯利公式在投资领域的先驱应用者,这本书用非常通俗的语言讲述了他如何用数学在赌场和华尔街都赚到了钱。
第六部分:用 insiders.bot 落地这套系统
看到这里,你可能会想:这套系统的逻辑我懂了,但我一个人怎么可能从零搭建?
好消息是,你不需要从零开始。
在做 insiders.bot (@insidersdotbot) 的过程中,这篇文章里提到的「主动管理基本定律」(也就是 IR = IC x √N ,你整个系统的表现等于单个信号的准确度乘以独立信号数量的平方根)给了我们非常大的启发。
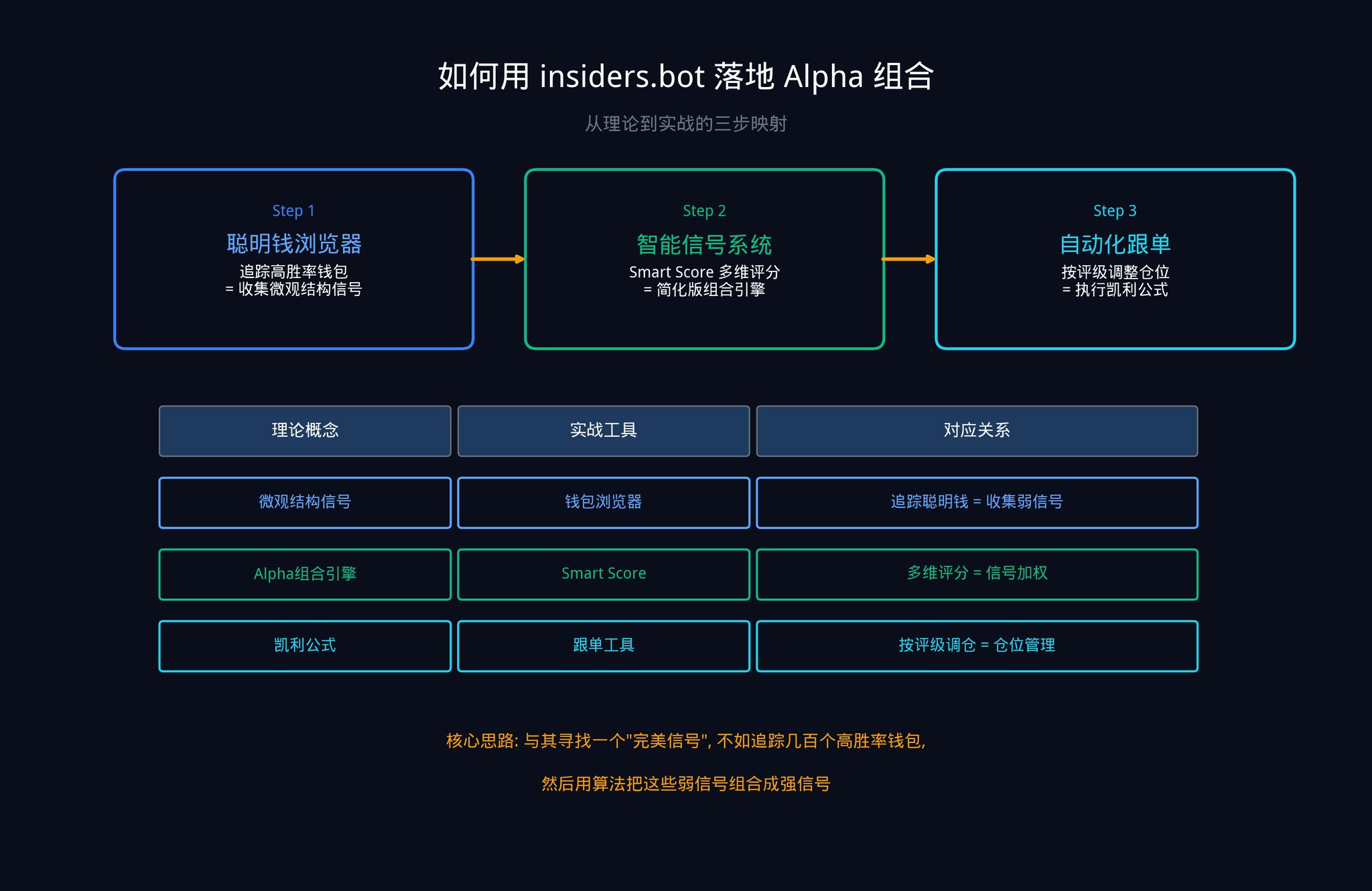
以下是你可以立刻开始操作的三个步骤。
第一步:用聪明钱浏览器收集你的信号原材料
打开 insiders.bot 的聪明钱浏览器。通过筛选面板,你可以按胜率、总盈亏、交易频率等维度,找到 Polymarket 上表现最好的钱包。
这些钱包的每一次异动,就是你的一个「微观结构信号」(还记得第二部分讲的五大信号类别中的第五类吗?)。单个钱包的信号可能很弱(IC 很低),但当你同时追踪几十个钱包时,你就在做文章里说的「信号组合」。这正是主动管理基本定律的核心:N 越大,IR 越高。
第二步:用智能信号系统实现 Alpha 组合
我们的智能信号系统(SIGNALS 标签页)本质上就是一个简化版的 Alpha 组合引擎。当优质钱包进行大额交易时,系统会生成信号,并通过 Smart Score 综合历史胜率、总盈亏、下注稳定性、分类表现、仓位规模等多个维度,给出一个强度评级。
LOW :达到基础标准,但交易员优势一般。对应低 IC 信号,需要更多信号来组合
MEDIUM :历史战绩良好,展现出坚定信念。对应中等 IC 信号,可以适度配置
HIGH :来自顶级表现钱包的重注交易。对应高 IC 信号,组合引擎给予高权重
这个评分系统做的事情,和第三部分 11 步引擎中的第 10 步(设置最优权重,也就是根据每个信号的独立贡献和稳定性来分配资金比例)本质上是一样的:根据多个维度的综合评估,给每个信号分配不同的权重。
第三步:用跟单工具执行你的凯利公式
当你收到一个 HIGH 评级的信号时,你可以使用我们的自动化跟单工具,设置按比例或固定金额跟单。
记住第五部分讲的经验凯利公式(f_empirical = f_kelly x (1 - CV_edge),也就是你的下注比例要根据你的不确定性来打折):你的估计越不确定,你应该下注越少。
对于 LOW 评级的信号,减小仓位。
对于 HIGH 评级的信号,可以适度加大仓位。让数学帮你做决策,而不是让情绪帮你做决策。
结语
让我们回到最开始的问题。
单个信号是微弱的。寻找那个完美的信号,完全是找错了方向。
主动管理基本定律(IR = IC x √N)在数学上证明了:组合许多微弱的独立信号,胜过寻找一个强信号。你的信息比率随着你部署的真正独立信号数量的平方根而增长。
11 步 Alpha 组合引擎为你提供了计算最优权重的精确方法。这些权重反映了每个信号的独立贡献,惩罚了噪音,消除了信号之间的共享方差。
应用于预测市场,这个框架将五个或更多的隐含概率信号转换成一个单一的组合估计。这个估计被证明比任何单个组件都更准确。
配合经验凯利公式进行仓位管理,它产生的头寸正确地反映了你实际应该有多自信,而不是你感觉有多自信。
复利最久的优势,建立在对你实际知道什么的最诚实的模型之上。
最后,我想让你思考一个问题:
如果组合了数百个信号的机构交易台,仍然只能达到 0.05 到 0.15 之间的信息系数,那么任何声称能从单一模型中以高置信度持续挑选赢家的系统,到底在说什么?
进阶阅读与参考文献
如果你想继续深入研究,以下是一些进阶资料:
入门级:
Harvard Stat 110: Introduction to Probability(免费在线教材)。概率论的基础,前 6 章就够了。
Edward Thorp, A Man for All Markets。凯利公式先驱的自传,用通俗语言讲述数学如何在赌场和华尔街赚钱。
进阶级:
Grinold & Kahn, Active Portfolio Management。量化投资领域的「圣经」,详细推导了主动管理基本定律。
MIT 18.06 Linear Algebra。Gilbert Strang 教授的经典课程,理解正交化的最佳资源。
高阶级:
Marcos Lopez de Prado, Advances in Financial Machine Learning。现代量化方法的必读之作,特别是关于交叉验证、特征重要性和正交化的部分。
Easley, Lopez de Prado & O'Hara (2012), Flow Toxicity and Liquidity in a High-frequency World, Review of Financial Studies. VPIN 指标的原始论文。
