Dawn Song:建立有责数据经济,实现隐私数据保护 | 世界区块链大会·武汉



2020年12月5日上午9点,2020世界区块链大会·武汉正式在武汉国际会展中心开幕。大会由巴比特主办,并得到了武汉市政府、江汉区政府、武汉市经信局、中国信通院等部门单位的大力支持。
在视频演讲《隐私数据保护与有责数据经济》中,加州大学伯克利分校教授、美国计算机协会(ACM) Fellow Dawn Song指出,数据对现代经济的发展至关重要。然而,当前的数据存在被滥用的情况,一方面用户无法控制自己的数据,不能从中受益;另一方面,企业也在数据处理方面困难重重。
因此,建立有责数据经济是唯一的解决方案。Dawn Song教授给出了由三个方面构成的解决方案:分别是技术支持、法律框架和激励模型。

以下为巴比特整理的演讲全文:
让我们先来看一些具体的例子,了解一下隐私数据领域为什么非常重要。
隐私数据为什么这么重要?
众所周知,机器学习能够主动学习,它能够接触到的所有数据,并跟着数据库的变化而发生改变。这些数据中有很多是非常隐私而且非常敏感的数据,因此当我们训练和部署自主学习的机器或系统时,个人的隐私数据能够被安全保护真的很重要。
这是一个具体的例子,向我们展示了为什么我们在开发产品时保护用户隐私的重要性,这也是我们近期与谷歌研究人员一起合作解决的工作重心。
今天,我们要一起探讨的核心问题是,自主学习网络会记住训练数据吗?黑客能否通过攻击系统的自主学习训练数据库提取到用户的个人隐私数据?
基于这种情况,我们来看语言自主学习模型的任务。文本语言学习模型是通过文本话术库,例如电子邮件数据库实现自主学习的,然后模型将尝试学习预测,它会尝试通过给定的单词序列,预测下一个字符。
特别是在这种情况下,我们开始了基于Enron电子邮件数据库的语言模型训练任务。每个人的电子邮件数据都包含每个真实用户的信用卡号和社会身份ID信息。攻击者即使不知道语言模型的细节,甚至不了解该语言模型的体系结构参数,就能通过简单地调用语言模型,获取用户的信息数据,这完全可以实现。仅仅通过原始数据和训练数据库获取用户的信用卡号和社会保险号。
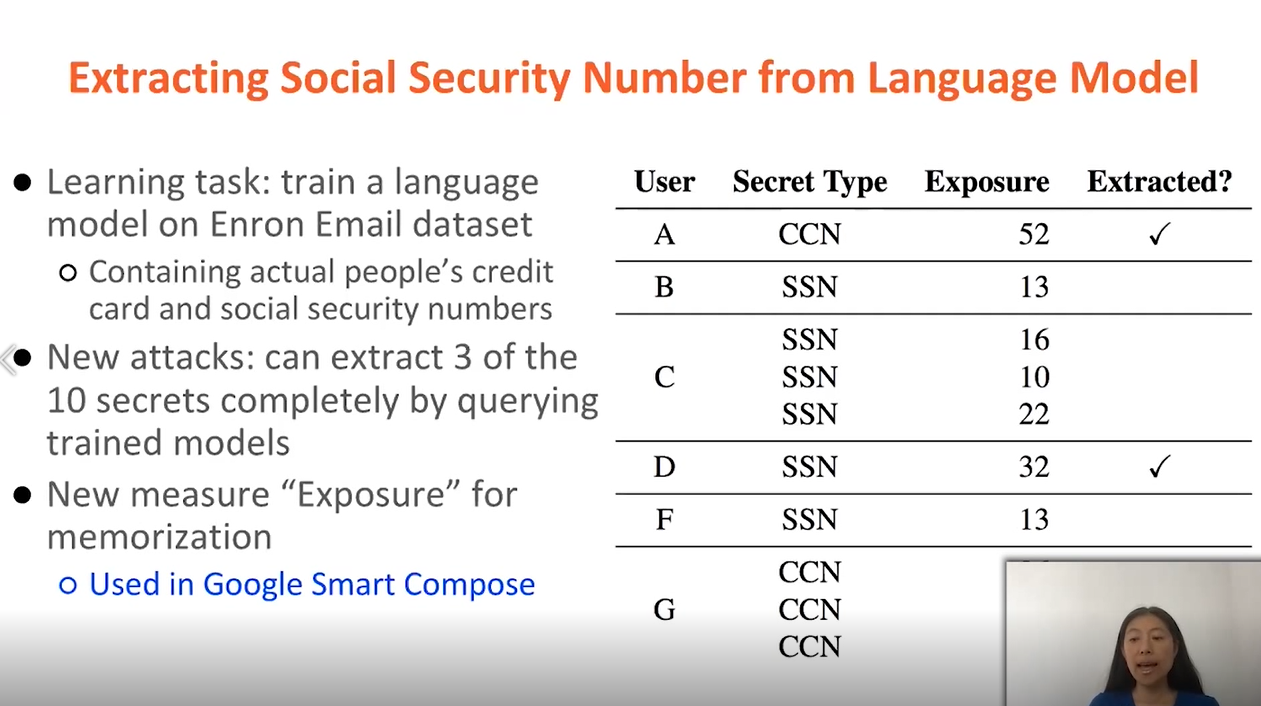
(图1)
这些例子说明了为什么在训练机器自我学习时隐私数据的安全处理方式非常重要。幸运的是,我们有一个解决方案。这个解决办法不仅让机器在模型中自我学习,取而代之的是一种“差异隐私”的数据训练模型,我们仍然可以保证很高的学习效率。与此同时,我们还可以显著增强隐私性,保护用户状态和隐私数据。
“差异隐私”是隐私保护更优解。尤其是,我们在其中看见了灵活操作的空间。如果满足以下特性,隐私信息差异化算法是完全可以实现的。
我们考虑相邻的数据库,一个数据库还有与其关联的其他信息,然后是其他数据库,例如Joe的数据。当我们在这两个相邻数据意义上计算随机算法函数时,让我们看一下数据计算结果。计算数据输出的结果非常相似。从本质上来说,这两个数据分布非常接近。
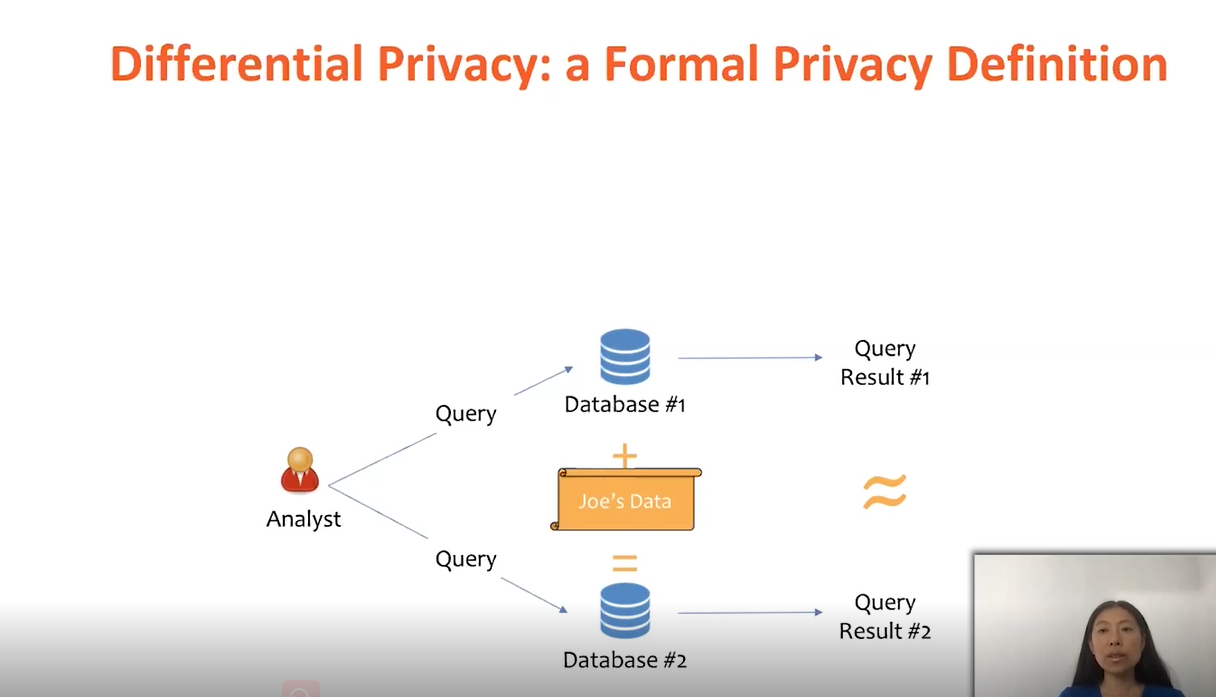
(图2)
但如果只看数据输出的话,攻击者将无法区分Joe的数据是否已包含在原始数据中。任凭怎么努力,在个人隐私数据策略中,数据都是被保护的。
我们最近的工作还开发了新型、美观且实用的自动化的方法,并能够验证这种机器算法。目前这项工作已经完成,而且得到了政策的支持与保证。该作品还赢得了顶级编程语言盛会的杰出人物奖项。
我们保护用户隐私,尤其是你向别人提到过的数据隐私,这只是一个例子。但同样的,也是隐私问题解决方案的冰山一角。
当前数据领域的痛点
众所周知,数据对现代经济至关重要。有很多数据,例如敏感的隐私数据被滥用或者被处理。个人用户和企业都面临前所未有的挑战。个人正在失去其如何使用自己隐私数据的控制。同样的是,许多隐私信息在用户不知情的情况下被卖了出去,数据信息的保护伞也已经匿名化。在某些个人身份可识别的地方,身份标识已被删除。
我认为很多工作经验表明,组织/企业在保护用户隐私方面的表现通常不太好。就像最近《纽约时报》的文章写的那样,他们可以通过匿名数据库中总统特朗普的手机位置数据,追踪特勤局特工的位置信息。
另一方面,用户也无法通过隐私数据获取收益,企业也继续遭受苦难。举个例子,他们继续遭受大规模数据泄露的困扰。同样的,对于企业而言,遵守诸如CCPA和GDPR之类的隐私法规变得越来越繁琐和昂贵。出于对隐私数据的担忧和其他一些因素,企业依旧很难真正利用好数据。
随着行业技术的发展,很多新技术虽然可以解锁实用程序,但通常会以牺牲隐私为代价。因此,我们不能继续目前的现状。当前状态会破坏人类价值和基本权利,阻碍社会前进的脚步。
建立有责数据经济需要基于三个框架
因此,我们迫切需要一个解决办法,建立有责数据经济。然而建立有责数据框架是非常复杂的,其原因有很多,比如程序便捷性与隐私保护之间不可调和的矛盾,再比如数据是非竞争性的,不能简单地复制物理世界中的概念和方法。
让我们以物理世界举例。如果A持有1个苹果,B就没有办法在同一时间持有同一个苹果。但是对于数据而言,同一份数据可以被复制成多份,公司和个体可以同时保存同样的数据,因为我们不能简单地复制模拟世界中的概念和方法来帮助解决数字世界中的问题。因此建立一个有责数据经济的框架就尤其需要技术和非技术解决方案的组合。
我们的框架至少需要以下三个组成部分: 技术支持、法律框架和激励模型。
技术解决方案方面,我们需要开发新技术去解决传统方案效率低下的问题。尤其是开发新技术的方式。新技术不仅像现有的数据加密一样保护数据,还能够保护使用中和计算机中的数据。甚至可以控制数据的使用方式,而无需复制原始数据,让解决方案能够更好的控制数据。此外,我们还要保护计算机输出不会泄露已输入的已输入的。
正如我们看到的那样,举个例子,分析数据通常不能为隐私提供足够的保护。幸运的是,在以不同的组件技术实现有责数据经济方面,我们已经看到了令人兴奋和迅速的进步,这包括安全计算,试图利用安全硬件等技术和解决方案以及基于加密的方法,如安全多方计算和同态加密等,来帮助保护计算过程不受信息一致性的影响。

(图3)
还有不同的隐私,以保护计算输出不产生有关个人的敏感信息。
联邦学习帮助数据所有者在其本地设备和机器上保存数据,并使不同的实体能够以分布式的方式一起训练机器模型,这还有助于进一步保护用户的数据隐私。
分布式账本可以提供一个不可篡改的日志来确保用户对数据的权利,确保用户策略如何使用这些数据以及提供数据使用的不可篡改的日志。
Oasis Labs在努力推进这些不同的组件技术,并将这些不同的组件技术编织在一起,以实现一个安全的分布式计算结构。它可以作为一个可靠的数据经济的平台,帮助解决我前面提到的许多挑战。
为了说明这些计算机技术以及可靠的数据经济平台的能力,这里我举一个例子,是我们一直在研究的基因学用例。
在直接面向消费者的基因学研究中,相关企业会收集用户的基因数据,为用户提供基因分析结果。然而,近段时间我们看到了一些面向消费者的基因企业出现了裁员的现象,并且特别指出对消费者隐私的担忧,这是延缓消费者普及的主要原因。
通过和基因公司在获取隐私服务的流程中合作,一旦投入使用,这将是用户首次成为自己基因数据的主人。也就是说,他们可以控制自己的基因数据以及数据的使用方式。他们的基因数据将以加密的形式存储。用户可以指定自己基因数据的使用方式。
举个例子,他们可以允许基因公司提供自己数据的基因分析。通过这次合作,基因公司可以使用安全计算的方法,但不会得到用户数据的原始副本。在同样的案例中,如果用户允许基因公司进行数据分析,基因公司可以在安全执行环境中运行数据,从而为用户提供计算结果,但基因公司将无法获得用户数据的原始副本。因此用户可以自主控制数据的同时,以隐私和可控的方式使用他们的数据。
除了改进技术之外,可靠的数据应用还需要更有效的监管,在这个领域存在很多挑战。例如,什么是数据权利?谁可以选择数据权利?
个人产权是现代经济的基石,帮助建立了现代经济学,推动了几个世纪的经济重大增长。然而,今天我们缺乏数据权利的充分框架。
构建数据权利可以帮助个人从他们的数据中获取价值,并且为经济增长做准备,解锁新的价值。我们需要探索一系列不同的概念和框架。
再次强调,我坚信安全和隐私将是AI应用的重大挑战之一。建立一个可靠的数据经济非常重要,这需要社区的努力,让我们一起解决这个重大挑战吧!

Ripple News: XRP’s Role in Blockchain Interoperability
The post Ripple News: XRP’s Role in Blockchain Interoperability appeared first on Coinpedia Fintech ...

Bitcoin Price Prediction: How Much Will 1 BTC Be Worth in May 2025?
The post Bitcoin Price Prediction: How Much Will 1 BTC Be Worth in May 2025? appeared first on Coinp...
Bull Market Reignited? Analyst Says Bitcoin Rally Mirrors June 2020 Setup
Bitcoin’s recent surge has kept its price firmly above the $100,000 price level, reflecting ongoing ...