


2026年4月底,一个名为“Owl Alpha”的匿名模型悄然出现在全球最大的大模型聚合分发平台OpenRouter上。没有官方公告,没有媒体发布会,甚至连开发团队信息也一片空白。但在接下来的约两个月时间里,这个神秘模型凭借惊人的吞吐量迅速攀升至平台调用量前列。据VentureBeat报道,该模型在匿名测试期间的月Token吞吐量达到约10.1万亿,日均处理559B Token,月环比增长242%。直到6月30日美团正式发布LongCat-2.0,这个靠5万张国产GPU训练出的1.6万亿参数大模型才揭开面纱,美团官方公告确认Owl Alpha即为其预览版,并称当前月调用量位列OpenRouter全球前三。
LongCat-2.0 的 MOPD 多专家融合架构示意(来源:longcatai.org)
一个预览版模型能在海外开发者平台斩获如此高的调用量,并非单一因素促成,而是技术架构与分发策略共同作用的结果。而在它之前,从智谱到小米,国产大模型似乎都热衷于在正式发布前通过OpenRouter进行“隐形练兵”。
Owl Alpha的两个月:匿名模型如何冲进OpenRouter前三?
要理解LongCat-2.0的高调用量,首先需要理解OpenRouter在当前大模型生态中的角色。对于开发者而言,OpenRouter提供了一个统一的API接口,可以接入全球数十家厂商的数百个模型。开发者在选择模型时,往往会在相同的Prompt下对比不同模型的速度、质量和价格。当一个新模型上线时,如果它表现出超越同价位模型的性能,或者提供了极具破坏力的价格,开发者社区的口碑传播会非常迅速。
Owl Alpha在OpenRouter上的爆发,正是遵循了这一逻辑。据美团官方公告显示,Owl Alpha在Hermes(Agent工作空间)、Claude Code、OpenClaw三大月调用量场景中分别排名第一、第二和第三。这三个场景的共同特征是高度依赖Agent能力,即模型需要反复读取代码库、进行多轮工具调用和长上下文推理。
高调用量并非偶然,除了模型本身的参数规模,更与其在特定场景的适配性和极具攻击性的定价策略有关。在匿名测试期间,Owl Alpha并未暴露其国产算力背景,纯粹以技术表现和价格征服开发者。VentureBeat报道的10.1万亿月Token吞吐量虽然为媒体估算,且OpenRouter官方未公开精确数字,但这一数据已经足以说明该模型在开发者社区中获得了极高的实际采用率。这种采用率不是靠营销预算买来的,而是靠真实的API调用堆出来的。
把代码库塞进缓存:LongCat-2.0如何重写Agent的计费逻辑
LongCat-2.0能够支撑如此庞大的调用量,核心在于其技术架构与商业策略的深度耦合。据美团官方公告,LongCat-2.0总参数量达1.6万亿,平均激活参数约480亿,动态范围在330亿至560亿之间,原生支持100万Token超长上下文。这种1.6T总参与48B激活的MoE(混合专家)架构,是目前大模型在性能与成本之间寻找平衡的主流选择。
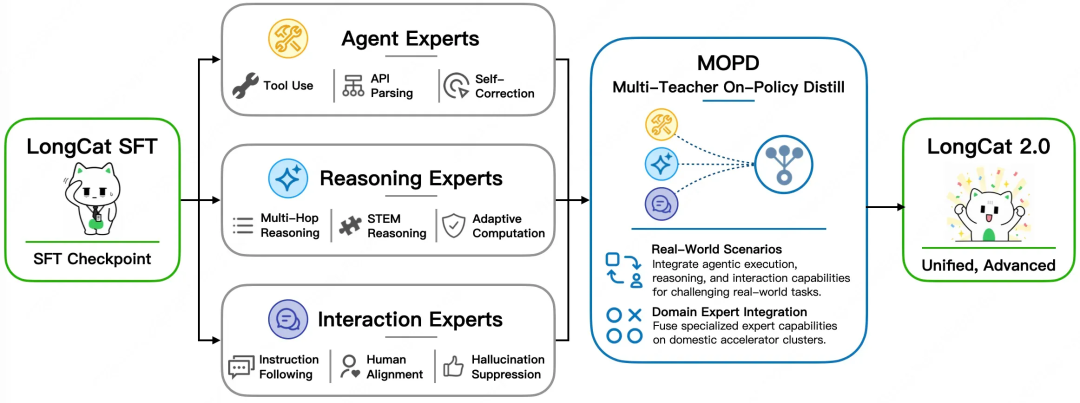
在技术架构上,LongCat-2.0融合了四项关键创新,每一项都直指Agent开发中的具体痛点。
首先是解决内存墙问题的LSA(LongCat Sparse Attention)稀疏注意力。处理100万Token的超长上下文,传统注意力机制的计算量是平方级增长的,这会导致极大的内存带宽瓶颈。LSA通过Streaming-aware Indexing将碎片化内存访问转为连续块读取,通过Cross-Layer Indexing实现跨层注意力索引复用,再通过Hierarchical Indexing进行粗到细的两阶段筛选,将长文本处理的计算量从平方级降至线性级。这解决了Agent在读取大型代码库时面临的内存墙问题。
解决了内存墙,接下来是算力分配的精细化。在MoE架构中,并非所有Token都需要复杂的计算。标点符号、功能词等简单Token如果被路由到复杂的专家网络,会造成算力浪费。LongCat-2.0在专家池中增设了“零计算专家”,路由到该专家的Token直接返回输入,不消耗计算资源。系统通过PID控制器动态调节专家偏置,维持平均激活参数在目标范围内。这就像是在高速公路上设置了快速通道,让简单任务快速通过,将算力留给复杂的递归推导。
算力分配优化后,通信延迟成为下一个需要攻克的瓶颈。ScMoE(Shortcut-connected MoE)采用跨层快捷连接,将前一个block的dense FFN计算与当前MoE层的dispatch/combine通信并行执行。这种流水线设计使得理论TPOT(Time-Per-Output-Token,每输出Token耗时)降低近50%,直接提升了模型的响应速度,这对于需要频繁交互的Agent场景至关重要。
最后是任务调度层面的MOPD(Multi-Teacher Optimization via Mixture of Specialized Experts)。在后训练阶段,LongCat-2.0将优化拆分为Agent、Reasoning、Interaction三组专用专家集群。Agent Experts负责工具调用和多轮API参数解析,Reasoning Experts负责多跳逻辑和数学推理,Interaction Experts负责指令遵循和安全护栏。推理时由门控网络根据任务类型动态调度。这意味着当开发者调用模型进行代码审查时,激活的是Agent专家;进行数学推导时,激活的是Reasoning专家。这种分工提升了模型在特定任务上的专业度。
然而,技术架构只是降本的基础,真正改变开发者算账逻辑的是其定价策略。据LongCat API定价页显示,其标准定价为输入¥5/百万Token,输出¥20/百万Token。但在限时折扣期间,价格降至输入$0.30/百万Token,输出$1.20/百万Token。更具颠覆性的是其“缓存命中免费”机制。
在Agent开发中,模型需要反复读取同一代码库或系统提示词。在传统的计费模式下,这些重复的输入Token每次都会产生费用,导致Agent的运行成本随交互轮数线性增长。LongCat-2.0的缓存命中免费机制,意味着只要输入的前缀部分在缓存中命中,就不扣费。这一设计直击Agent场景的成本痛点,被许多开发者视为“改变Agent成本经济学”的创举。
为了更直观地理解LongCat-2.0的性价比,我们可以参考以下基于公开生态信号整理的对比表。
| 模型 | 厂商 | SWE-bench Pro 得分 | 输出标准价 ($/M tokens) | 输出限时价 ($/M tokens) | 开源协议 | 数据口径说明 |
|---|---|---|---|---|---|---|
| Claude Opus 4.8 | Anthropic | 69.2 | $25.00 | 无 | 闭源 | 厂商自报/第三方聚合 |
| GLM-5.2 | 智谱 | 62.1 | $4.40 | 无 | MIT | 厂商自报/第三方聚合 |
| Qwen3.7 Max | 阿里 | 60.6 | $3.75 | 无 | 部分开源 | 厂商自报/第三方聚合 |
| LongCat-2.0 | 美团 | 59.5 | $2.95 | $1.20 | MIT | 厂商自报,未进入Scale AI标准化公开榜 |
| MiniMax M3 | MiniMax | 59.0 | $2.40 | 无 | 开源 | 厂商自报/第三方聚合 |
| GPT-5.5 | OpenAI | 58.6 | $30.00 | 无 | 闭源 | 厂商自报/第三方聚合 |
| DeepSeek V4 Pro Max | DeepSeek | 55.4 | $0.87 | 无 | MIT | 厂商自报/第三方聚合 |
需要说明的是,上表中的SWE-bench Pro分数均为各厂商自报或第三方聚合数据,不同模型可能在不同批次或评测条件下进行测试,横向对比仅作参考。此外,LongCat-2.0的59.5分为美团自报,截至发稿时尚未进入Scale AI标准化公开排行榜。Scale标准化公开榜上,GPT-5.4 (xHigh) 以59.1%的标准化分数领先,且标准化分数普遍比厂商自报低10至30分。即便如此,LongCat-2.0在限时折扣价$1.20/百万Token的加持下,叠加缓存免费机制,其在开源模型中的价格破坏力依然显著。
跑分前三与“编程不如预期”:LongCat-2.0的实际能力边界
厂商公布的跑分数据往往描绘了一幅完美的图景,但开发者的实际体验却更为复杂。LongCat-2.0在SWE-bench Pro取得59.5分,SWE-bench Multilingual达77.3分,Terminal-Bench 2.1得分为70.8。这些数据表明该模型在软件工程基准测试中处于开源模型的第一梯队。
然而,在Reddit的r/LocalLLaMA社区中,开发者的反馈呈现出不同的视角。有用户在测试后表示:“It's not good in coding, very good in reviews though. Instruction following is also pretty good. A little bit of a waste with that parameter...”(编程能力不如预期,代码审查和指令遵循不错,参数规模有些浪费)。这反映出模型在通用代码生成任务上可能不如在代码审查和指令遵循任务上表现出色。在r/SillyTavernAI社区,也有用户反馈该模型在角色扮演场景中倾向于代替用户说话,存在交互体验上的瑕疵。
这种跑分与实际体验的落差,在大模型行业并不罕见。厂商自报跑分通常是在特定的测试环境和提示词下获得的,而开发者的实际使用场景往往更加多样化和复杂。LongCat-2.0在MOPD架构中专门设置了Agent、Reasoning、Interaction三组专用专家,这可能使得模型在特定任务上表现优异,但在通用编程生成上仍有局限。
此外,LongCat-2.0的开源承诺仍需时间验证。截至6月30日发布日,其HuggingFace页面显示模型权重为“coming soon”,尚未提供下载。虽然官方宣布采用MIT开源协议,对企业用户友好,可嵌入闭源商业产品,但在权重实际落地前,开发者仍持观望态度。同时,其宣称的100万Token超长上下文的实际信息保持率,也缺乏第三方独立验证,如Needle-in-a-Haystack等测试的公开数据。这些限制都意味着LongCat-2.0的实际能力边界,还需要在更广泛的开发者实践中去界定。
从Pony到Owl:国产大模型为何热衷于海外“偷跑”?
LongCat-2.0通过Owl Alpha在OpenRouter上的匿名测试,并非孤立事件。梳理2026年以来的行业动态,可以发现一种明显的趋势:国产大模型在正式发布前,越来越热衷于在OpenRouter上进行匿名预览。
2026年2月,OpenRouter上线了匿名模型“Pony Alpha”,后被证券时报等媒体确认其真实身份为智谱AI的GLM-5。该模型在编程和Agent优化上表现突出,且提供免费调用。紧接着在3月,匿名模型“Hunter Alpha”出现,后被确认是小米的MiMo-V2-Pro,拥有1T参数和1M上下文。4月底,Owl Alpha上线,即美团LongCat-2.0。这些案例构成了国产大模型“隐形练兵”的清晰时间线。
为什么国产大模型会选择这种在海外平台匿名“偷跑”的方式?
首先,这是一种高效的冷启动与真实反馈获取策略。在国内市场,大模型发布往往伴随着极高的舆论关注和参数内卷压力。厂商一旦官宣,就会立刻被置于与所有竞品的显微镜式对比中。而在OpenRouter上匿名上线,可以剥离品牌光环和舆论包袱,让模型纯粹以技术表现和价格面对全球开发者。开发者社区的反馈是真实且残酷的,他们只关心调用是否顺畅、价格是否便宜、输出是否高质量。这种“盲测”环境能为厂商提供最真实的极限吞吐反馈和Bug发现机会。
其次,这是对基础设施稳定性的一次实战检验。LongCat-2.0全程基于5万张国产AI ASIC卡完成全流程训练与推理。这样规模的国产算力集群,在稳态日吞吐超过1T tokens/day的实战压力下,是否会出现不可恢复的loss尖峰或通信瓶颈,只有在真实的全球流量冲击下才能验证。OpenRouter提供了一个现成的、高并发的流量入口,帮助美团测试其国产算力集群的极限承载能力。
最后,市场窗口的客观存在也推动了这一策略。美国出口管制限制了部分闭源模型(如Claude Fable 5/Mythos 5、GPT-5.6)的对外供应,这在客观上为国产模型在海外市场留出了窗口。通过OpenRouter的匿名测试,国产模型能够迅速填补部分开发者对高性能、低成本模型的需求空缺,积累用户基础和口碑,为后续的正式发布和商业化铺路。
从Pony到Hunter再到Owl,国产大模型在OpenRouter上的“隐形练兵”已经从一种偶然的尝试,演变为一种行业共性的冷启动策略。对于开发者而言,这意味着他们能更早接触到经过真实流量检验的模型,并以更具竞争力的价格进行开发测试;对于行业而言,这种基于真实API调用量的冷启动模式,正在逐渐替代单一权威榜单,成为检验大模型基础设施稳定性和实际能力的新标准。