


原文作者:星期五,深潮 TechFlow
Anthropic 刚刚交出了一份纸面上无可挑剔的成绩单。
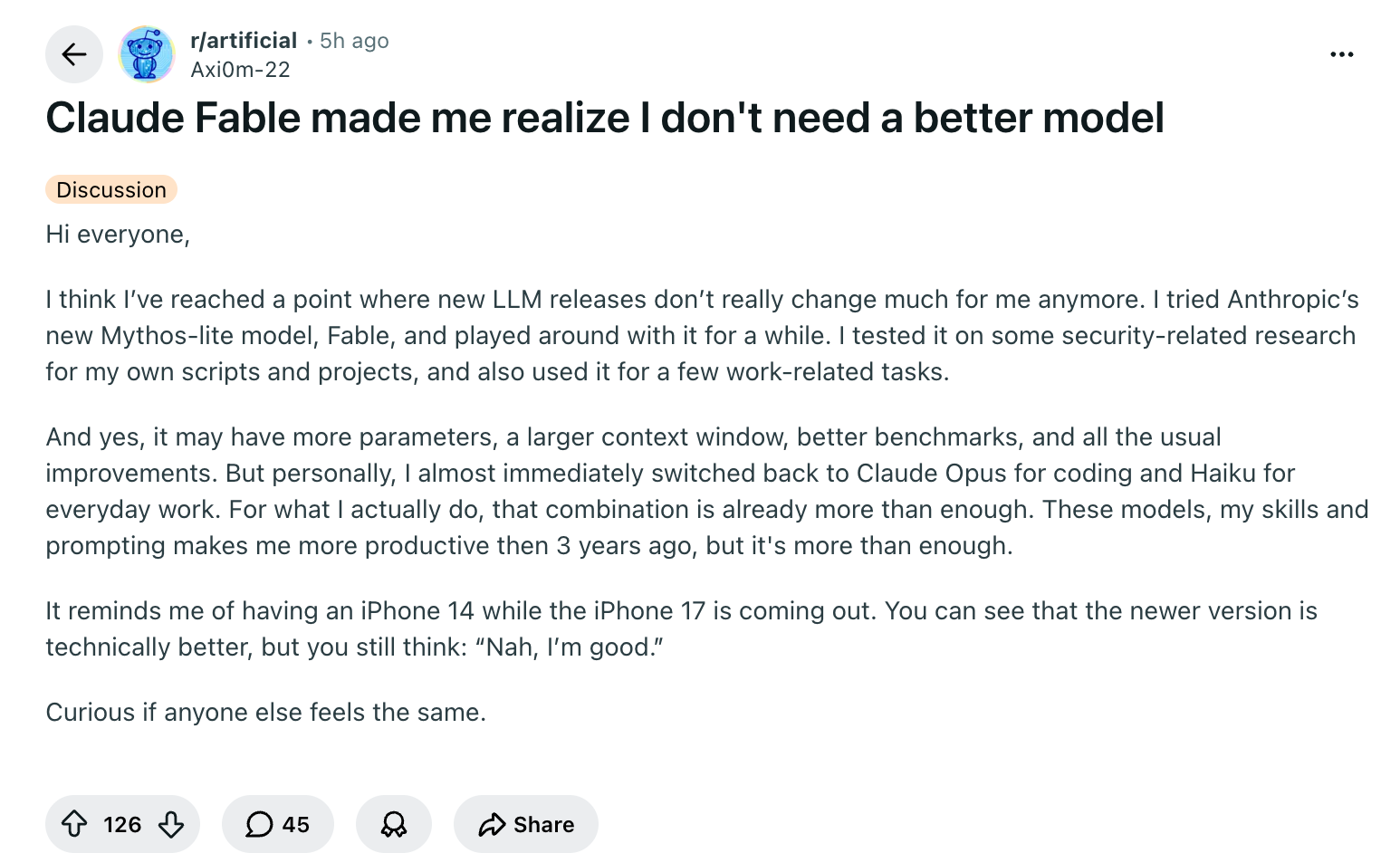
6 月 9 日发布的 Claude Fable 5 是该公司首个面向公众开放的 Mythos 级模型,在真实软件工程任务基准 SWE-Bench Pro 上拿下 80.3%,领先自家上一代旗舰 Opus 4.8 约 11 个百分点,领先 GPT-5.5 超过 20 个百分点。
但用户的反应泼了一盆冷水。
发布三天后,r/artificial 版块(周访问量 30.5 万)的一篇热帖标题写道:「Claude Fable 让我意识到,我不需要更好的模型了。」发帖人 Axi0m-22 说,他用 Fable 跑了一段时间安全研究和日常工作,然后几乎立刻切回了 Opus 写代码、Haiku 处理杂活。他打了个比方: 这就像拿着 iPhone 14 看 iPhone 17 发布,「你知道新的更好,但你想的是:算了,我这个挺好。」
高赞区被「够用派」占领:模型审美疲劳成主流情绪
排名第一的评论获得 42 个赞:「除了更大的上下文窗口, 我从 Opus 4.5 开始就不再觉得需要更强的模型了。 」
另一位用户 hyprlab 的表态拿到 13 个赞:「换一个烧 token 更狠的模型,我看不到对我工作流的好处,Opus 4.8 高强度模式已经足够舒服。」
这类发言背后有一个共同的成本账本。
Fable 5 的 API 定价为每百万输入 token 10 美元,接近 Opus 4.8 的两倍。用户 siromega37 说得直白:「token 消耗更高,但没有投资回报。我觉得我们正在看到平台期,泡沫终将被刺破。」
用户 hobopwnzor 给出了更系统的解读:「我们已经在 S 型曲线的顶部待了一阵子。近期的进步主要来自工具调用和外围工程,不是模型本身的能力。」
安全护栏成最大槽点:「90%的用途直接被拒」
如果说「够用」还只是情绪,那么对安全护栏的抱怨就是具体的产品问题了。
按照 Anthropic 官方说明,Fable 5 与仅向少数机构开放的 Mythos 5 共享同一底层模型,区别在于 Fable 加装了安全分类器:涉及网络安全等高风险领域的请求会被拦截,转由 Opus 4.8 代答。官方称这套机制调校得偏保守,平均在不到 5%的会话中触发,且会误伤无害请求。
在这条 Reddit 帖子下,触发率的体感显然远高于 5%。获得 17 个赞的用户 jradoff 说,他让 Fable 检查自己代码的安全性,结果「只要提到安全相关的事,它基本都拒绝处理」,然后被回退到 Opus。另一条 12 赞的评论更不客气:「你想用它干的事 90%都会被拒,等于没用。」
付费用户的怨气更重。订阅 200 美元档位的用户 kaitava 写道:「我付着双倍的用量费,想让它做一次安全审查,结果被降级到 Opus。这下我对它的一切都不喜欢了,就等 OpenAI 追上来。」
对于一款主打能力跃迁的旗舰产品,「为安全付出的可用性代价」正在成为用户决定是否买单的核心变量。
反方声音:重度任务用户的体感是「夜与昼」
热帖之下并非没有反对者,而且反方的画像相当清晰:任务越重,评价越高。
用户 Phylaras 的评论拿到 15 个赞:「Fable 对我产生了实质区别。那些对上下文窗口要求巨大的复杂任务,它抓出了之前没被发现的错误。」一位自称在做高能物理仿真的用户表示,单个仿真模型动辄 8000 到 1 万行代码、上百个模型相互作用,「有个能独立连续工作、理解环境细节的模型,对我来说太值得期待了」。
最激烈的反驳来自用户 Navetz:「说实话,用过这个模型的人会觉得这种帖子是疯话。对我来说它聪明得判若两人,我一直在不停地用。我跟非技术朋友解释:这相当于从大学生球员直接换成 NBA 首发。」
也有人给出了折中的用法。用户 ready-eddy 建议把 Fable 当「规划者和修复者」,而不是日常的「建造者」,除非不在乎烧钱。另一条评论总结得更像使用手册:用 Fable 算表格是选错了模型,用 Haiku 跑 16 个智能体的复杂任务同样是选错了模型,「不存在天生的坏模型,只有用错场景的模型」。
跑分与体感脱钩之后,公开 AI 还会更强吗
这场争论里最有意思的一条评论,把话题从产品引向了行业结构。
用户 KedMcJenna 提出了一个「公开 AI 冻结论」:普通人能摸到的模型可能会永远停在当前水平附近,而企业和政府精英将持续获得更强的私有模型,「我们知道的至少有 Mythos,很可能还有更强的、我们永远不会听说的模型」。
这条评论指向一个事实:Mythos 5 确实不对公众开放,目前仅通过 Project Glasswing 计划提供给网络防御机构和关键基础设施企业。
把跑分和舆情放在一起看,结论并不矛盾。
基准测试衡量的是能力上限,而 Reddit 高赞区反映的是日常需求的天花板。当大多数用户的任务在 Opus 4.6 时代就已被满足,更强的模型只能在物理仿真、超长上下文这类极端场景里证明自己。模型厂商面对的不再是「做不做得到」的问题,而是「谁需要、愿意付多少钱、能容忍多少安全摩擦」的问题。
发布三天,Fable 5 在跑分榜和舆论场拿到了两份完全不同的成绩单。哪一份更接近真相,要看 Anthropic 接下来调整安全分类器的速度,以及重度用户的钱包投票。


