


原文作者:Sleepy.md
2026 年 4 月 24 日,DeepSeek V4 预览版正式发布。
这款包含 1.6 万亿参数的 Pro 版本和 2840 亿参数的 Flash 版本的国产大模型,把最核心的卖点砸向了市场,百万上下文,成了所有官方服务的免费标配。几乎在同一时间段,大洋彼岸的 OpenAI 也端出了 GPT-5.5,它的算力更庞大,Agent 功能更丰富,但价格也要贵得多。
「百万上下文」翻译成大白话,意味着 AI 不再是一条只能记住你前几句话的「金鱼」,而是变成了一个能一口气吞下三本《三体》、一秒钟看懂一部两小时电影、还能顺便帮你把错别字挑出来的「超级大脑」。
举个最直接的例子,你可以把公司过去三年的所有合同、邮件、财报,一股脑扔给 V4,让它帮你找出那笔被藏在第 47 页附件里的违约条款。过去,这件事需要一个律师团队;现在,它是免费的。
GPT-5.5 把这种超级大脑明码标价,标准版每百万输入 Token 要 5 美元,输出 30 美元;而面向高阶任务的 GPT-5.5 Pro 版本,更是卖到了每百万输入 30 美元、输出 180 美元的天价。
但根据 DeepSeek 官方定价,V4-Flash 缓存命中的输入每百万 Token 仅 0.2 元人民币,输出 2 元;即便是比肩顶级闭源模型的 V4-Pro,缓存命中输入为 1 元,缓存未命中输入为 12 元,而输出价格仅为 24 元
大家总以为中美 AI 竞争是模型能力的赛跑,实际上,这早就变成了一场商业模式的分道扬镳。
OpenAI 曾经是那个高喊「造福全人类」的屠龙少年,现在却在卖着价格昂贵的精装商品房;而 DeepSeek,正在用近乎免费的算力,把 AI 变成水电煤。
当 OpenAI 变成精明的包工头时,DeepSeek 为什么要不计成本地把顶尖 AI 变成免费的自来水?这场定价权转移的背后,到底隐藏着怎样的暗流?
乌兰察布的冷风
大模型的决胜局,在内蒙古零下 20 度的机房里。
就在 V4 发布前不久,DeepSeek 的招聘启事里多了一个让人意外的岗位:数据中心高级交付经理与高级运维工程师,月薪最高 3 万,14 薪,驻场内蒙古乌兰察布。
这是一家曾经标榜「极简、纯粹、只做算法」的轻资产公司。在过去两年里,他们最骄傲的标签就是「四两拨千斤」,用不到 600 万美元的训练成本,打出了让美股 AI 板块暴跌的 DeepSeek-R1。
但 V4 的庞大算力需求,加上美国越来越紧的算力封锁,彻底打碎了这种轻资产的田园诗。
2025 年,美国商务部进一步收紧了对华 AI 芯片的出口管制,英伟达 H100、H800 已经断供,就连降级版的 H20 也被拉进了管控名单。这意味着 DeepSeek 未来的算力扩张,必须全面转向华为昇腾生态。在 V4 的发布说明中,官方明确表示新模型得到了「华为昇腾加持」,并透露下半年昇腾 950 超节点批量上市后,Pro 的价格还会大幅下调。
这一转向,不是在代码里改几行适配层就能完成的,它需要从零开始,在物理层面建立一套完整的国产算力基础设施。
V4 的万亿参数规模(预训练数据高达 33 万亿 Token),加上百万上下文的庞大计算需求,意味着你需要成千上万张昇腾芯片,需要能容纳这些芯片的机房,需要为这些机房供电的电网,需要在零下 20 度的寒风里维持这些机器不宕机的运维团队。
梁文锋把方法论从比特世界打到了原子世界。算力,最终都要在钢筋水泥和输电线里落地生根。
一边是穿着格子衫在硅谷敲代码、喝着手冲咖啡的 AI 精英,一边是裹着军大衣去内蒙古草原深处守机房的运维人员。这种差异,构成了今天中国 AI 抵抗算力封锁的底色。乌兰察布的冷风,成了中国 AI 最强的物理外挂。
从纯算法公司转型为自建机房的「重资产」玩家,意味着 DeepSeek 告别了「小力出奇迹」的游击战时代,正式穿上了重装步兵的铠甲。这种转型的代价是巨大的,修机房、买芯片、拉网线,每一项都是无底洞。更重要的是,这种重资产模式意味着运营成本会呈指数级上升,而 DeepSeek 的商业化收入依然极其有限。这种定价策略,本质上是在用亏损换生态,用免费换基础设施的话语权。
一个曾经拒绝所有巨头、靠量化交易自己掏钱补贴 AI 的硬汉,在这个无底洞面前,还能撑多久?
200 亿美元的妥协
4 月,DeepSeek 传出了启动首次外部融资的消息,目标估值高达 3000 亿人民币(约 440 亿美元),计划增资 500 亿,其中对外募资 300 亿。腾讯与阿里争抢入局的传闻甚嚣尘上。
很多人以为,这是因为建机房太费钱了。但实际上,DeepSeek 融资的核心驱动力,除了买显卡,更是因为「纯粹的技术理想」,在巨头的人才绞肉机面前,不堪一击。
在 V4 研发的关键冲刺期,国内大厂对 DeepSeek 开启了疯狂的定向挖角。从 2025 年下半年至今,DeepSeek 至少 5 名核心研发成员确认离职。第一代模型核心作者王炳宣去了腾讯,V3 核心贡献者罗福莉被雷军千万年薪挖至小米,而 R1 核心作者郭达雅则加盟了字节跳动的 Seed 团队。
这是市场经济最赤裸的运作方式,当你的竞争对手手握无限弹药,而你坚持用自有资金维持运转时,人才市场就是你最脆弱的软肋。你可以要求天才们为了改变世界的理想降薪加班,但当大厂把一张写着千万现金和期权的支票拍在桌子上,并许诺无限的算力资源时,理想主义的定价权就不在你手里了。
梁文锋的困境,其实是每一个试图在中国做「慢公司」的创业者都会遇到的困境。在一个大厂能用钱把任何人买走的市场里,「不融资、不商业化、只做技术」的路线,是极其奢侈的。它的代价,是你必须接受自己的团队随时可能被对手用钱清场。

这 3000 亿估值的融资,不是梁文锋对资本的妥协,而是他为了保住 V4 研发阵型,向大厂发起的一场赎人战争。他必须坐上资本的牌桌,用同样的真金白银,让留下来的人有足够的理由继续留下来。
腾讯与阿里的可能入局,意味着 DeepSeek 从此不再是那个孤独的、纯粹的技术理想主义者。它变成了一家有外部股东、有商业化压力的公司。这种转变的代价,是梁文锋曾经最引以为傲的那种「不受外部压力干扰的研究自由」,将不可避免地被稀释。
但他没有选择。
当理想主义被迫穿上资本的铠甲,支撑这台庞大机器继续运转、支撑乌兰察布机房日夜轰鸣的底气,究竟来自哪里?
另一种「大力出奇迹」
答案不在算法里,在电网里。
硅谷现在最焦虑的不是芯片不够,而是电不够。马斯克在田纳西州孟菲斯疯狂建设超级数据中心,OpenAI 甚至开始讨论投资核电站,微软宣布重启宾夕法尼亚州的三里岛核电站来为 AI 数据中心供电。算力的尽头是电力,这是一个极其冰冷的物理常识。
在美国,一个大型 AI 数据中心的用电量,相当于一座中等城市的日常用电。而美国的电网,是一张建于 20 世纪 50 年代的老旧网络,扩容缓慢,区域割裂,根本跟不上 AI 时代的算力扩张速度。
而支撑中国 AI 追赶美国的,不仅是那些拿着千万年薪的算法天才,更是那些默默无闻的特高压输电线。
乌兰察布的数据中心之所以能拔地而起,靠的是内蒙古丰富的绿电,以及中国世界第一的电网调度能力。公开数据显示,乌兰察布绿电装机容量达 1940.2 万千瓦,占比约 65.9%,当地低价绿电较东部地区便宜约 50%。再加上年均气温仅 4.3℃,自然冷却期接近 10 个月,能让设备节能 20% 到 30%。
当 DeepSeek V4 运行时,真正为其输血的,是中国庞大且极其廉价的电力基础设施。这是另一种维度的「大力出奇迹」。
这里有一个极其有趣且残酷的历史对照。1986 年,美国用《美日半导体协议》把日本的半导体产业打趴下了,强迫日本开放市场、接受价格管控,日本半导体的全球市场份额从 1986 年的 40% 一路跌到 2011 年的 15%。日本用了三十年都没能缓过来。
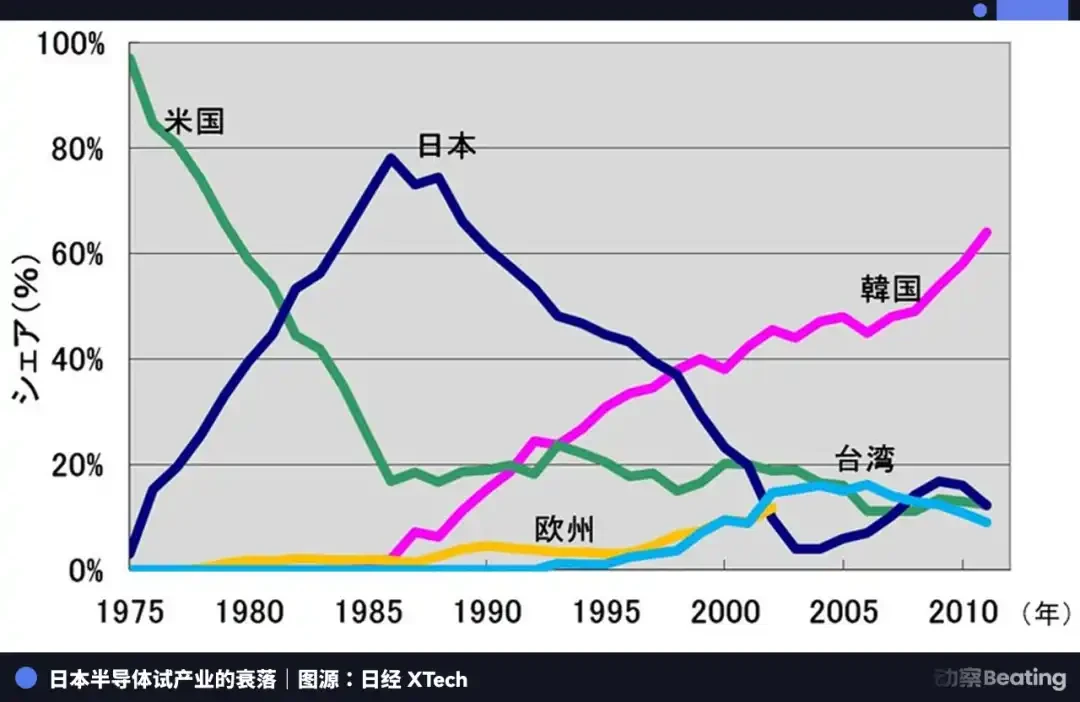
今天,美国试图用同样的逻辑锁死中国 AI,封锁芯片、限制算力、切断技术供应链。但中国的反击路径,和日本完全不同。日本当年的失败,在于它的半导体产业高度依赖美国的技术授权和市场准入,一旦被切断,就失去了独立生存的能力。而中国 AI 的反击,是从最底层的物理基础设施开始重建的,自己造芯片、自己建机房、自己拉电网、自己开源模型。
这是一种极其笨重、极其耗钱、但也极其难以被「绞杀」的路线。当硅谷在云端修建华丽的巴别塔时,中国在泥土里挖战壕。
如果云端的算力拼杀是一场极其惨烈的重资产消耗战,除了去内蒙古修机房、拉电线,我们还有没有逃离云端霸权的另一条路?
逃离云端
当硅谷巨头们把数据中心修得越来越大,甚至像 OpenAI 一样筹划着千亿美元级别的算力集群时,中国的反击线,却悄悄转移到了地下。
对抗美国算力封锁的终极武器,其实不是造出比 H100 更强的芯片,而是把大模型塞进每个人的手机里。
既然我们在云端机房里拼不过重火力,那我们就把战场拉回到 14 亿台智能手机和边缘设备上。这是一种典型的游击战打法,而且是一种极难被封锁的打法,你可以禁止出口高端 GPU,但你没办法没收每个中国人口袋里的手机。
2026 年,伴随着 DeepSeek 引发的算力焦虑,中国手机厂商小米、OPPO、vivo 开始了一场疯狂的「端侧转移」。他们不再满足于仅仅把手机作为一个调用云端 API 的显示器,而是通过极致的模型蒸馏和压缩,把一个缩小版的超级大脑,硬生生塞进了几千块钱的国产手机里。
这种技术路线的核心,是「蒸馏」。简单来说,就是用一个超级大模型(老师)去训练一个小模型(学生),让小模型学会老师的「思维方式」,而不是死记硬背老师的所有「知识」。经过极致的蒸馏和量化压缩,一个原本需要几百张 GPU 才能跑的大模型,被压缩到只有 1.2GB 到 2.5GB 大小,在一颗手机芯片上就能流畅运行。
像 MNN Chat 这样的移动端 AI 应用,已经能让用户在手机上本地运行 DeepSeek R1 蒸馏模型。这种端侧 AI 的意义在于,你不需要时刻连着 5G 信号,不需要每个月给硅谷巨头交 100 美元的订阅费。大模型就在你的口袋里,断网也能跑,不用给云端算力花一分钱。
既然我修不起集中供暖的超级锅炉房,那我就给每家每户发一个小火炉。
当然,端侧 AI 并不完美。受限于手机芯片的算力和内存,端侧模型的能力上限远不如云端的超大模型。它能帮你写一封邮件、翻译一段文字、总结一篇文章,但如果你想让它帮你推导一个复杂的数学定理,或者分析一份几百页的法律合同,它还是会力不从心。
但这已经足够了。因为对于绝大多数普通人来说,他们需要的 AI,从来就不是那个能推导数学定理的超级大脑,而是一个能帮他们处理日常琐事的「贴身助理」。
当大模型变得极其廉价,甚至可以装进口袋里时,它将如何改变那些被硅谷遗忘的角落?
全球南方的数字平权
如果你坐在曼哈顿全景玻璃办公室里,你大概率会觉得,GPT-5.5 涨价到 100 美元是值得的,因为它能帮你在一秒钟内写完一份完美的并购财报。
但如果你站在东非乌干达的一片玉米田里,面对着因为气候异常而枯黄的庄稼,100 美元的订阅费没人能交得起,因为乌干达的人均月收入不到 150 美元。
硅谷的巨头们在讨论如何用 AI 统治世界,而乌干达的农民和东南亚的穷学生,却因为 DeepSeek 的开源,第一次走进了数字时代。
GPT-5.5 服务于付得起钱的人,并且它的语料库几乎全是英语。如果你用斯瓦希里语或者爪哇语去问它一个问题,它不仅回答得磕磕巴巴,而且消耗的 Token 是英语的几倍。硅谷巨头因为「商业回报率低」,主动放弃了这些边缘市场。
而中国的开源模型,成了全球南方的数字基础设施。
在乌干达,当地的非政府组织 Sunbird AI,用基于中国开源模型 Qwen 微调出的 Sunflower 系统,把能支持的本地语言从 6 种一举扩展到了 31 种。这个系统现在被部署在乌干达政府的农业推广系统里,用斯瓦希里语给农民发送种植建议。
在马来西亚,科技公司用开源底座微调出了符合伊斯兰教法的 AI 模型,不仅支持马来语和印尼语,还确保输出内容符合穆斯林市场的宗教与文化标准。从印尼的数字身份系统到肯尼亚的斯瓦希里语医疗问答,中国技术正在渗透进这些国家的社会底层架构。
全球最大 AI 模型 API 聚合平台 OpenRouter 在 2026 年初发布的数据显示,中国 AI 模型在该平台的 Token 消耗量首次超过美国竞争对手。在某一统计周内,全球前 10 大热门模型共消耗 8.7 万亿 Token,其中中国模型占比达到约 61%。
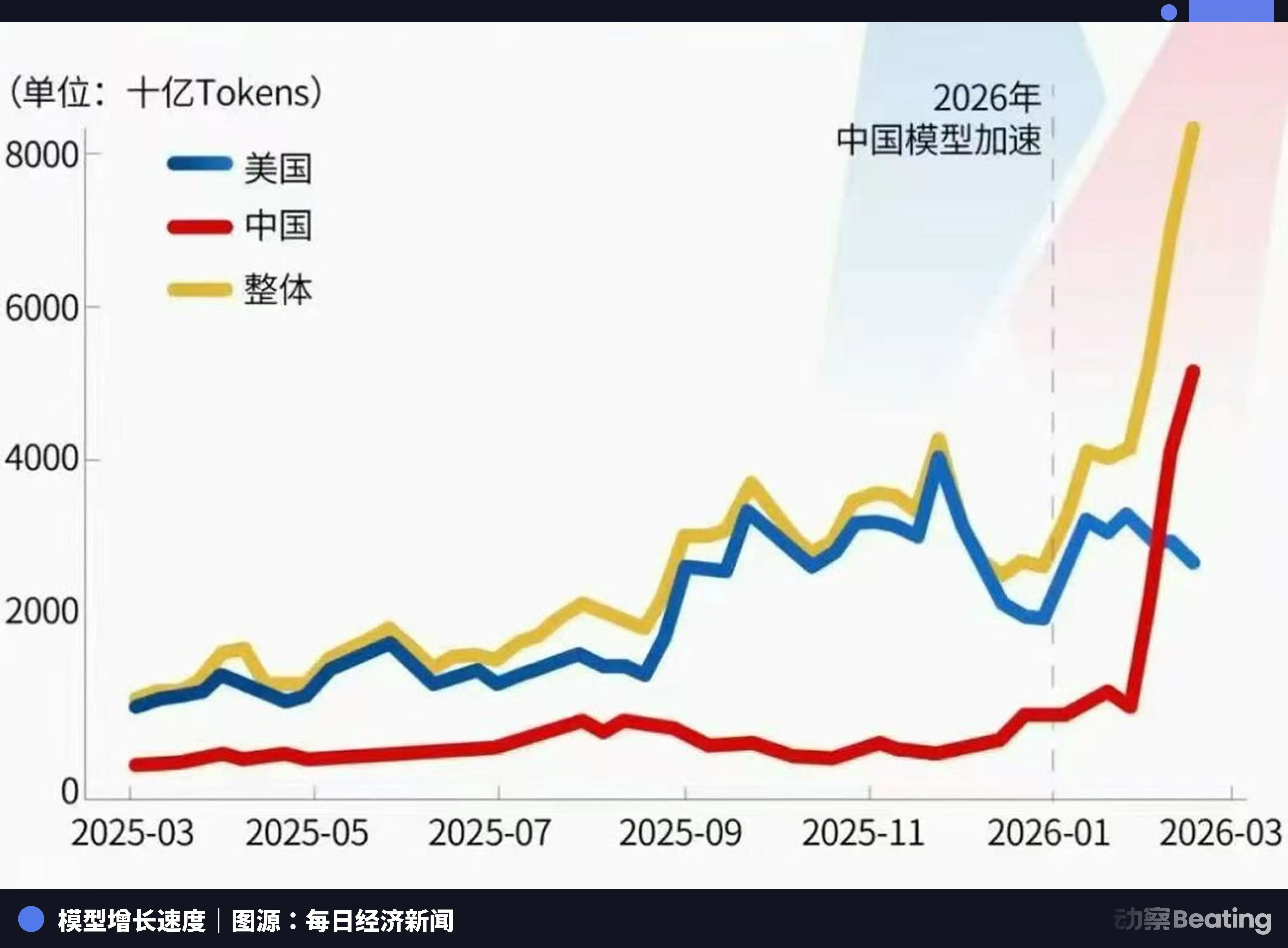
开源打破了美国对 AI 话语权的垄断,让资源匮乏的发展中国家跨越了数字鸿沟。这不是什么中美争霸的宏大叙事,这是 AI 时代真正的「农村包围城市」。
中国的 AI 开源战略,客观上正在成为一种极其有效的「软实力」输出。当硅谷的巨头们在云端筑起高墙,试图成为新时代的数字地主时,那些付不起租金的「技术难民」,终于在开源和端侧的泥土里,找到了属于自己的火种。
自来水
技术从来就不应该是高高在上的奢侈品。
硅谷造出了极其精美的商品房,门禁森严,只对 VIP 开放。但我们修了一条通向千家万户的自来水管。
这条水管的起点,在内蒙古零下 20 度的机房里,在特高压输电线的轰鸣中,在 3000 亿估值的战争里。它的每一段都沉重、都昂贵、都充满了被迫与妥协。梁文锋曾经想做一家纯粹的技术公司,但现实逼着他去建机房、去融资、去和大厂抢人。他没有选择,因为他选择了一条更难的路,不把 AI 做成奢侈品,而要把它做成自来水。
而这条水管的终点,在一台几千块钱的国产手机上,在乌干达农民粗糙的手指间,在每一个渴望跨越数字鸿沟的普通人生活里。
算力的围墙建得再高,也挡不住流向低处的自来水。


