


原文作者:深潮 TechFlow
谷歌一篇号称「将 AI 内存占用压缩至 1/6」的论文,上周引发美光、SanDisk 等全球存储芯片股超 900 亿美元市值蒸发。
然而论文发布仅两天,算法所「碾压」的对比方——苏黎世联邦理工学院博士后高健扬发布万字公开信,指控谷歌团队在实验中用单核 CPU 的 Python 脚本测试对手、却用 A100 GPU 测试自己,并在投稿前已被告知问题后仍拒绝修正。知乎阅读量迅速突破 400 万,Stanford NLP 官方账号转发,学术界与市场同时震动。
这场争议的核心问题并不复杂:一篇由谷歌官方大规模推广、直接引发全球芯片板块恐慌性抛售的 AI 顶会论文,是否系统性地歪曲了一项已发表的先行工作,并通过刻意制造的不公平实验,塑造了虚假的性能优势叙事?
TurboQuant 做了什么:把 AI 的「草稿纸」压薄到原来的六分之一
大语言模型在生成回答时,需要一边写一边回头翻看之前算过的内容。这些中间结果被临时存在显存里,业内叫做「KV Cache」(键值缓存)。对话越长,这张「草稿纸」越厚,显存消耗越大,成本也越高。
谷歌研究团队开发的 TurboQuant 算法,核心卖点就是把这张草稿纸压缩到原来的 1/6,同时号称精度零损失、推理速度提升最高 8 倍。论文于 2025 年 4 月首次在学术预印本平台 arXiv 发布,2026 年 1 月被 AI 领域顶级会议 ICLR 2026 接收,3 月 24 日由谷歌官方博客重新包装推广。
技术层面,TurboQuant 的思路可以简单理解为:先用一种数学变换把杂乱的数据「洗」成统一格式,然后用预先算好的最优压缩表逐个压缩,最后再用一个 1 比特的纠错机制修正压缩带来的计算偏差。社区独立实现已验证其压缩效果基本属实,算法层面的数学贡献是真实存在的。
争议不在于 TurboQuant 能不能用,而在于谷歌为了证明它「远超竞争对手」,做了什么。
高健扬公开信:三条指控,条条戳中要害
3 月 27 日晚 10 点,高健扬在 知乎发布长文 ,同步在 ICLR 官方审稿平台 OpenReview 提交正式评论。高健扬是 RaBitQ 算法的第一作者,该算法 2024 年发表在数据库领域顶级会议 SIGMOD,解决的是同一类问题——高维向量的高效压缩。
他的指控分三条,每一条都有邮件记录和时间线佐证。
指控一:用了别人的核心方法,全文不提。
TurboQuant 和 RaBitQ 的技术核心有一个关键的共同步骤:在压缩数据之前,先对数据做一次「随机旋转」。这步操作的作用是把原本分布不规则的数据变成可预测的均匀分布,从而大幅降低压缩难度。这是两个算法最核心、最接近的部分。
TurboQuant 作者自己在审稿回复中也承认了这一点,却在论文全文中从未正面说明这一方法与 RaBitQ 的关联。更关键的背景是:TurboQuant 的第二作者 Majid Daliri 在 2025 年 1 月主动联系高健扬团队,请求帮忙调试他基于 RaBitQ 源码改写的 Python 版本。邮件中详细描述了复现步骤和报错信息——换言之,TurboQuant 团队对 RaBitQ 的技术细节知之甚详。
ICLR 的一位匿名审稿人也独立指出两者使用了相同的技术,要求充分讨论。但在最终版论文中,TurboQuant 团队不仅没有补充讨论,反而把原本正文中对 RaBitQ 的(已经不完整的)描述移到了附录。
指控二:无凭无据称对方理论「次优」。
TurboQuant 论文直接给 RaBitQ 贴上了「理论次优」(suboptimal)的标签,理由是 RaBitQ 的数学分析「较为粗糙」。但高健扬指出,RaBitQ 扩展版论文已经严格证明其压缩误差达到了数学上的最优界——这个结论发表在理论计算机科学的顶级会议上。
2025 年 5 月,高健扬团队曾通过多轮邮件详细解释了 RaBitQ 理论的最优性。TurboQuant 第二作者 Daliri 确认已告知全体作者。但论文最终仍保留了「次优」的表述,没有给出任何反驳论据。
指控三:实验对比中「左手绑人、右手持刀」。
这是全文最具杀伤力的一条。高健扬指出,TurboQuant 论文在速度对比实验中叠加了两层不公平条件:
第一,RaBitQ 官方提供了优化过的 C++代码(默认支持多线程并行),但 TurboQuant 团队没有使用,而是用自己翻译的 Python 版本来测试 RaBitQ。第二,测试 RaBitQ 时用的是单核 CPU 且关闭了多线程,而 TurboQuant 用的是 NVIDIA A100 GPU。
这两个条件叠加的效果是:读者看到的结论是「RaBitQ 比 TurboQuant 慢数个数量级」,却无从知道这个结论的前提是谷歌团队把对手绑住手脚之后再比赛跑。论文中没有充分披露这些实验条件的差异。
谷歌的回应:「随机旋转是通用技术,不可能每篇都引」
据高健扬披露,TurboQuant 团队在 2026 年 3 月的邮件回复中表示:「随机旋转和 Johnson-Lindenstrauss 变换的使用已经是该领域的标准技术,我们不可能引用每一篇使用了这些方法的论文。」
高健扬团队认为这是在偷换概念:问题不是要不要引用所有用过随机旋转的论文,而是 RaBitQ 是在完全相同的问题设定下、最先将这一方法与向量压缩结合并证明其最优性的工作,TurboQuant 论文理应准确描述两者的关系。
Stanford NLP Group 官方 X 账号转发了高健扬的声明。高健扬团队已在 ICLR OpenReview 平台发表公开评论,并向 ICLR 大会主席及伦理委员会提交正式投诉,后续还将在 arXiv 发布详细技术报告。
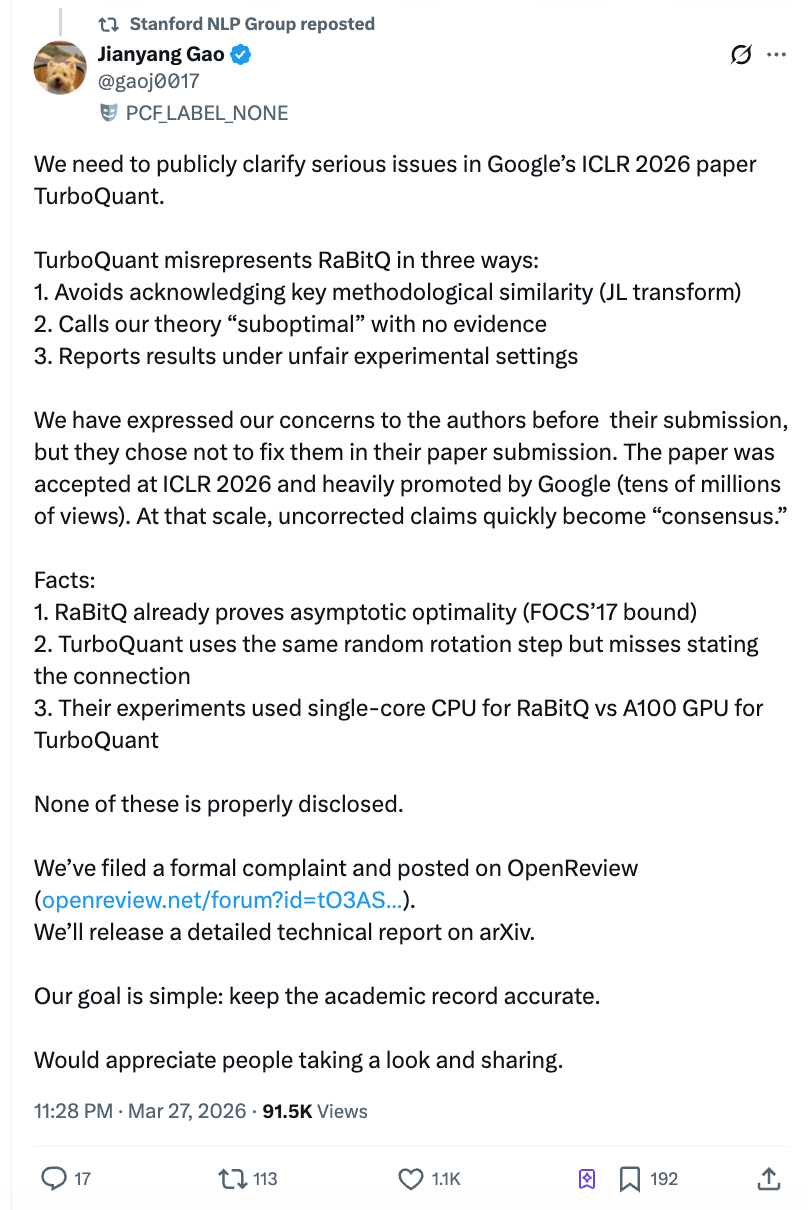
独立技术博主 Dario Salvati 在分析中给出了相对中立的评价:TurboQuant 在数学方法上确实有真实贡献,但与 RaBitQ 的关系远比论文表述的要紧密。
900 亿美元市值蒸发:论文争议叠加市场恐慌
这场学术争议发生的时间节点极为微妙。谷歌 3 月 24 日通过官方博客发布 TurboQuant 后,全球存储芯片板块遭遇猛烈抛售。据 CNBC 等多家媒体报道,美光科技连续六个交易日下跌,累计跌幅超过 20%;SanDisk 单日跌幅达 11%;韩国 SK 海力士跌约 6%,三星电子跌近 5%,日本铠侠跌约 6%。市场恐慌逻辑简单粗暴:软件压缩能把 AI 推理内存需求降低 6 倍,存储芯片的需求前景将遭到结构性下调。
摩根士丹利分析师 Joseph Moore 在 3 月 26 日的研报中反驳了这一逻辑,维持美光和 SanDisk 的「增持」评级。Moore 指出,TurboQuant 压缩的仅是 KV Cache 这一特定类型的缓存,而非整体内存使用量,并将其定性为「正常的生产率改进」。富国银行分析师 Andrew Rocha 同样援引杰文斯悖论认为,效率提升降低成本后反而可能刺激更大规模的 AI 部署,最终拉升内存需求。
旧论文、新包装:AI 研究到市场叙事的传导链风险
据技术博主 Ben Pouladian 分析,TurboQuant 论文于 2025 年 4 月就已公开发布,并非新研究。3 月 24 日谷歌通过官方博客重新包装推广,市场却将其当作全新突破进行定价。这种「旧论文、新发布」的推广策略,叠加论文中可能存在的实验偏差,折射出 AI 研究从学术论文到市场叙事传导链条中的系统性风险。
对 AI 基础设施投资者而言,当一篇论文声称实现了「数个数量级」的性能提升时,首先需要追问的是基准对比的条件是否公平。
高健扬团队已明确表示将继续推动问题的正式解决。谷歌方面尚未对公开信的具体指控作出正式回应。


