





你可能听说了, Ethereum 的分片路线图已经基本上取消了执行分片,如今只专注于数据分片,从而使 Ethereum 的数据空间吞吐量最大化。
你可能也看到了最近关于模块化区块链的讨论,深入地研究了 Rollup,了解了 volitions 与 validiums,然后也听说了「数据可用性解决方案」。
但是,在这个过程中你可能也会产生一个疑问:「到底什么是数据可用性?」。
在我们开始解释这个问题之前,我们可以先来回顾一下大多数区块链的工作原理。
交易、节点与恶名昭著的区块链三难困境问题
当你遇到了一个新的 OHM 分叉,如果它有着高得惊人的年利率,那你肯定会毫不犹豫的按爆「质押」那个按钮。但是,当你在上 Metamask 提交交易时会发生什么?
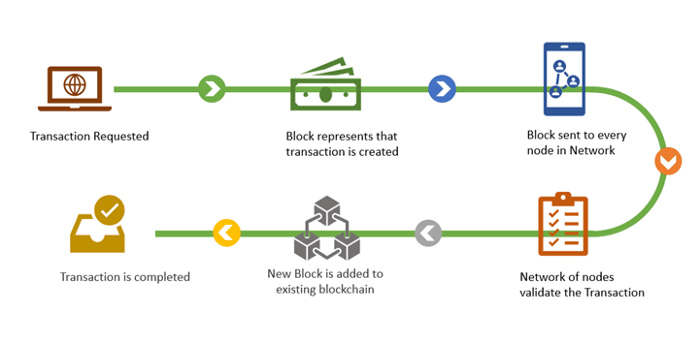
简单来说,你的交易会进入到内存池当中,假设你给矿工或验证者的贿赂足够高,你的交易会被放入到下一个区块中,并被添加到区块链上供后人查阅。然后,这个包含着你交易的区块会被发送到区块链的节点网络中。之后,全节点将下载这个新的区块,执行并计算这个区块中包含的每一笔交易(其中当然也包括你的那笔交易),同时确保这些交易都是有效交易。比如,在你的交易中,这些全节点可能会验证你是否有从其他人那里窃取资金,以及你是否有足够的 ETH 来支付 Gas 费等等。因此,全节点的重要任务便是对矿工和验证者执行区块链的各项规则。
正是因为这一机制,传统区块链便出现了扩容的问题。由于全节点会检查每笔交易以验证它们是否遵循区块链的规则,因此区块链无法在不提高硬件水平的情况下每秒钟处理更多的交易(更好的硬件会强化全节点的功能,而更强大的全节点可以验证更多交易,这样就能有更多可以包含大量交易的区块了)。但是,如果运行全节点的硬件要求提高了,那么全节点的数量就会变少,而去中心化的进程也会受到影响——如果能够确保矿工/验证者遵守规则的人少了的话,那情况就相当危险了(因为信任假设数量就会增加)。
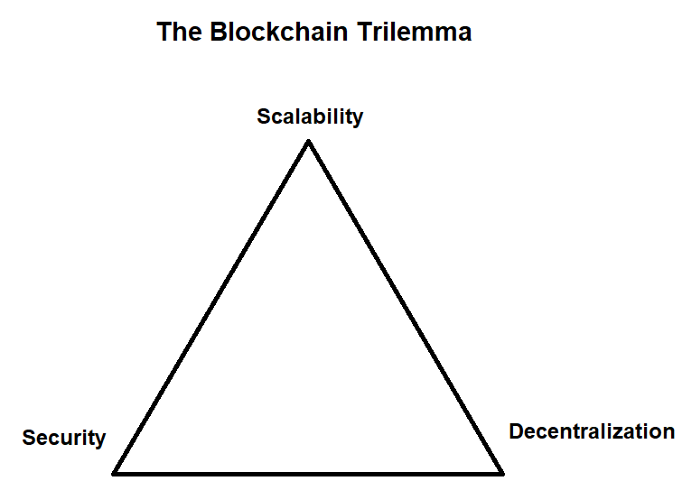
数据的可用性是我们不能同时拥有扩容、安全与去中心化的主要原因之一
这种机制也说明了在传统单片式区块链中保证数据可用性的重要性:区块生产者(矿工/验证者)必须公布并提供他们生产区块的交易数据,以便全节点来检查他们的工作。如果区块生产者不提供这些数据的话,全节点就无法检查他们的工作,而且也就无法确保他们有在遵守区块链规则。
现在你应该理解了为什么数据可用性在传统单片式区块链中非常重要了,接下来让我们来探讨一下它在人见人爱的可扩展性解决方案——Rollup 中扮演着怎样的角色。
在 Rollup 背景下,数据可用性发挥着怎样的重要性
让我们先来重温一下 Rollup 是如何解决可扩展性问题的:与其提高运行全节点的硬件要求,为什么我们不去减少全节点需要验证有效性的交易数量?我们可以将交易的计算和执行工作从全节点交由给一个更强大的计算机(也被称为序列器)来完成。
但这是否也意味着我们必须信任序列器?如果全节点的硬件要求要保持在较低水平,那么在检查工作时,它们的速度肯定会慢于序列器。那么,我们如何确保这个序列器提出的新区块是有效的呢(也就是说,要保证该序列器并没有在窃取大家的资金)。鉴于这个问题一直被反复提及,我相信你已经知道了这个问题的答案,但也请你继续耐心读完接下来的内容(
对于 Optimistic Rollup,我们可以靠欺诈证明来维持序列器的可靠性(除非有人提交了欺诈证明,表明序列器中包含有一个无效或恶意的交易,我们一般都默认序列器能够可靠运作)。但是,如果我们想让其他人也能计算欺诈证明,那么他们便会需要序列器所执行的交易数据,以便提交欺诈证明。换句话说,序列器必须提供交易数据,否则没人能保证 Optimistic Rollup 序列器的可靠性。
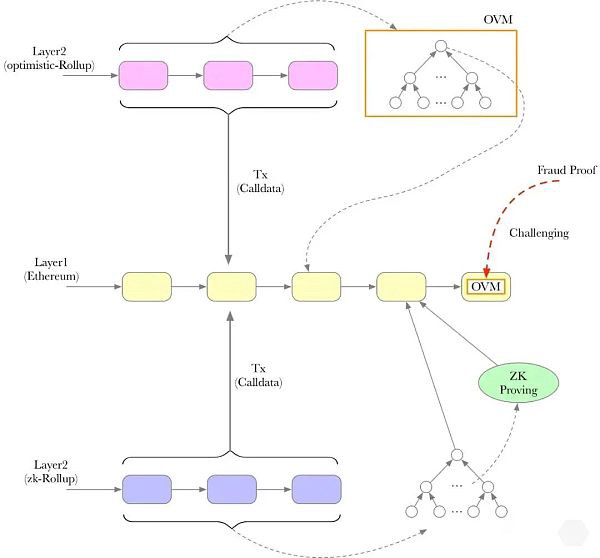
有了 ZK Rollup,保证序列器的可靠性就变得简单多了——序列器在执行一批交易时必须提交有效性证明(ZK-SNARK 或 ZK-STARK),而这个有效性证明便可以保证序列器中不会出现无效或恶意交易。此外,任何人(甚至是智能合约)都可以轻易地验证这些证明。但对于 ZK-Rollup 的序列器来说,数据可用性依然是举足轻重,这是因为我们作为 Rollup 的用户,如果想快速投资于 Shitcoin 的话,就需要知道我们在 Rollup 上有多少账户余额。但如果交易数据不可用的话,我们就无法知道我们的账户余额,也就无法再与 Rollup 进行互动。
上文让我们明白了,人们一直以来推崇 Rollup 的原因。鉴于全节点不一定要能跟上序列器的速度,那我们为什么不直接把它变成一台功能强大的计算机?这一改变将让序列器每秒执行大量的交易,从而降低了 Gas 费,并令所有人都感到满意。但是,序列器还是需要提供交易数据,也就是说,即使序列器是一台真正的超级计算机,它实际能计算的每秒交易数量仍将受到它所使用的底层数据可用性解决方案或数据可用性层的数据吞吐量的限制。
简而言之,如果 Rollup 所使用的数据可用性解决方案或数据可用性层无法储存 Rollup 序列器想要转储的数据量,那么序列器(以及 Rollup)即使想处理更多的交易,也都无能为力了。与此同时,这也会让 Ethereum 上的 Gas 费用升高。
这正是数据可用性之所以极其重要的原因——如果数据可用性得到了保证,我们就可以规范 Rollup 序列器的行为,而如果 Rollup 准备最大化其交易吞吐量,数据可用性解决方案或数据可用性层数据空间吞吐量的最大化也将变得至关重要。
但你可能已经意识到,我们尚未完全解决序列器能否正常运作的问题。如果 Rollup 主链全节点的计算速度不需要跟上序列器的话,序列器就可以扣留很大一部分的交易数据。问题在于,主链节点如何才能强制序列器将数据转储到数据可用性层之上?而如果节点不能做到这一点的话,我们就根本不会在可扩展性方面取得任何进展,因为这样的话我们就不得不去信任序列器或自己出资购买超级计算机了。
上述问题也被称为「数据可用性问题」。
「数据可用性问题」的解决方案
数据可用性问题最直接的解决方案是,强制全节点下载由序列器转储的所有数据到数据可用性层或解决方案上。但与此同时,我们也清楚这对我们并无帮助,因为这需要全节点跟上序列器的交易计算速度,并提高运行全节点的硬件要求,最终会阻碍去中心化的发展。
因此很明显,我们需要一个更好的解决方案来解决这个问题,而且幸运的是,我们碰巧就有一个。
数据可用性证明
每当序列器转储一个新的交易数据块时,节点可以通过数据可用性证明来进行数据「采样」,以确保这些数据确实是由序列器所提供的。
虽然数据可用性证明的工作原理涉及大量数学计算以及技术术语,但我还是会尽力向大家解释清楚
我们首先可以要求由序列器转储的交易数据块进行擦除编码处理,而这也就意味着原始数据的规模将变大一倍,之后新的以及额外的数据则被编码为冗余数据(这就是我们所说的擦除代码)。擦除数据编码之后,我们便可以用任意 50% 擦除编码的数据来恢复原始数据的全部内容。

擦除代码技术和游戏《堡垒之夜》中能让你在那次吓到猫以后继续欺负你那个讨人厌的表弟和他的朋友,使用的是一个技术。
不过请注意,交易数据块进行了擦除编码处理以后,序列器要想做出不当行为必须扣留该区块 50% 以上的数据。但如果该区块没有被擦除编码的话,那么序列器只留存 1% 的数据就可以做出不当行为了。所以说,通过对数据进行擦除编码处理,全节点就更能确保序列器能够实现数据可用性了。
尽管如此,我们也想尽可能确保序列器能提供全部数据。在理想情况下,我们希望序列器能达到的可靠性与我们直接下载整个交易数据块一样高,而事实上,这是完全可以实现的:全节点可以随机从该区块下载一些数据。如果序列器行为不端,全节点将有小于 50% 的几率被欺骗,即在序列器试图扣留数据时随机下载一部分数据。这是因为,如果序列器意图行为不当、扣留数据,那么它们必须扣留大于 50% 擦除编码的数据才行。
与此同时,这也就意味着,如果全节点可以两次进行该操作的话,就可以大幅降低被欺骗的可能性。全节点通过随机选择另一块数据进行第二次下载,就可以把被欺骗的概率降到 25% 以下。事实上,全节点第七次随机下载数据时,其未能检测到序列器扣留数据的几率将小于 1%。
这一过程被称为使用数据可用性证明的抽样,或者也可以直接称为数据可用性抽样。它的效率非常高,因为该抽样可以让节点在只下载序列器于主链上发布的一小部分数据的情况下,就可以保证其效果与下载并检查整个区块相一致(节点可以使用主链上的 merkle 根来找到要采样的内容和区域)。为了让大家有一个更直观的感受,你可以想象一下,如果你在小区散步 10 分钟就能消耗和跑步 10 公里一同样多的热量,是不是就能感受到数据可用性抽样的强大了。
如果主链全节点可以进行数据可用性采样的话,我们就能确保 Rollup 序列器不出现错误行为。我们现在都应该感到高兴,因为我们已经可以确信 Rollup 的确能够扩展我们最喜爱的区块链。但在你想退出这个网页之前,是否还记得我们仍需要找到一种方法来扩展数据可用性本身?如果我们想让世界上所有人都加入到区块链当中,从而挣到更多的钱,那我们就需要建设 Rollup;如果我们想用 Rollup 来扩展区块链,那我们不仅需要限制序列器做出不当行为,而且我们还必须扩展数据空间的吞吐量,从而降低序列器转储交易数据的成本。
数据可用性证明也是扩展数据空间吞吐量的关键
近期,一个有着专注于扩展数据空间吞吐量路线图的 layer 1 便是 Ethereum 了。它希望通过数据分片来扩展数据空间的吞吐量,这也就意味着不是每个验证器都会像目前的节点那样继续下载相同的交易数据(验证器也能运行节点)。相反,Ethereum 将从本质上把它的验证器网络分为不同的分区,该操作也被称为「分片」。假设你有 1000 个验证器,并且它们都用来存储相同的数据,那么如果你把它们分成 4 组,每组 250 个验证器,你一瞬间就将 Rollup 转储数据的空间增加了 4 倍。这看起来很简单,对吗?
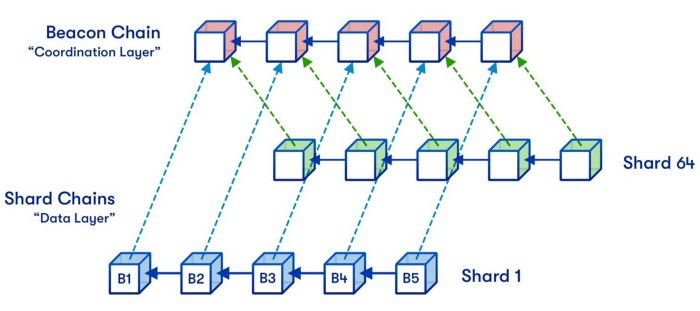
Ethereum 在其「近期」数据分片路线图中正尝试设置 64 个数据分片
然而,问题是,一个分片内的验证器只能下载被转储到他们分片上的交易数据。而且这意味着一个分片内的验证器不能保证序列器转储的全部数据都可用——它们只能保证转储到他们分片的数据是可用的,但不能保证其他分片的数据可用。
因为,我们可能会遇到这样的情况:一个分片中的验证器不能确定序列器是否发生了错误行为,因为他们不知道其他分片中发生了什么,而这一问题也可以用数据可用性抽样来解决。如果你是一个分片中的验证者,那么你就可以使用其他每一个分片中的数据可用性证明进行数据抽样。这样一来,你就相当于是每个分片的验证者了,数据可用性也就因此得到了保证,而 Ethereum 也可以安全地进行数据分片了。
其他一些区块链,也就是 Celestia 和 Polygon Avail 也想大规模扩展其数据空间吞吐量。与其他大多数区块链不同的是,Celestia 和 Polygon Avail 都只做两件事:下单区块与交易,以及成为数据可用性层。这意味着,为了保证 Celestia 与 Polygon Avail 验证者的可靠,我们非常需要一个去中心化的节点网络,以确保其验证者有在正确存储和订购交易数据。但是,由于这些数据不需要做任何处理(即执行或计算),你就并不需要使用全节点来保证他们的可靠性了。相反,能够完成数据可用性采样的轻节点将也可以完成全节点的工作,而如果有很多轻节点都可以用数据可用性证明进行采样的话,就足以让验证者在保证数据可用性方面负起责任了。也就是说,只要有足够的节点使用数据可用性证明进行数据可用性采样(鉴于数据可用性证明甚至可以用手机来计算,想做到这一点相当容易),你就可以扩大区块,提升验证者的硬件要求,从而提高数据空间的吞吐量。

现在让我们来回顾一下:数据可用性问题也许是区块链三难困境的关键,对我们所有在扩展方面的努力都造成了影响。幸运的是,我们能够利用数据可用性证明这一核心技术来解决数据可用性问题。这让我们得以大规模扩展数据空间的吞吐量,降低了 Rollup 转储大量交易数据的成本,以便其处理足够多的交易,从而让全世界的人都能参与进来。此外,数据可用性证明也让我们可以在无需信任 Rollup 序列器的情况下,就可以保证它的可靠性。希望这篇文章能让你理解为什么要想充分发挥 Rollup 的全部潜力,数据可用性是如此的重要了。

Bitcoin Price Consolidates Below Resistance, Are Dips Still Supported?
Bitcoin Price Consolidates Below Resistance, Are Dips Still Supported?
XRP, Solana, Cardano, Shiba Inu Making Up for Lost Time as Big Whale Transaction Spikes Pop Up
XRP, Solana, Cardano, Shiba Inu Making Up for Lost Time as Big Whale Transaction Spikes Pop Up
Justin Sun suspected to have purchased $160m in Ethereum
Justin Sun suspected to have purchased $160m in Ethereum